栈溢出
原理
函数栈的结构如图。
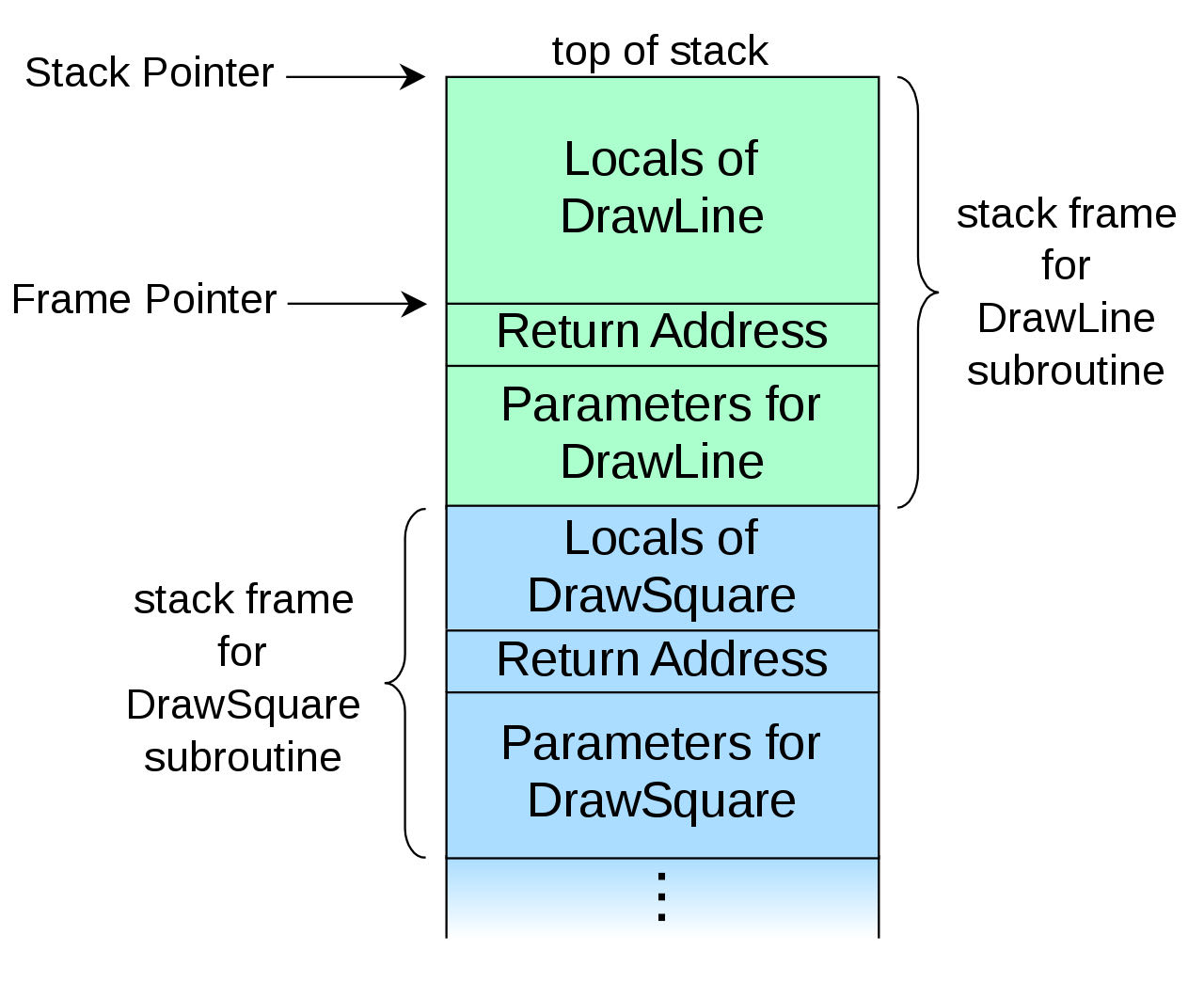
假设函数DrawSquare()调用了函数DrawLine(),被调用的栈就会建在调用方的栈的上方。整个栈往上生长。首先压入的是调用方传入的参数,然后是被调用者执行完后的返回地址,紧跟其后是图中未画出的8位的saved %ebp(32位和64位保存的方式不同,但都是8位,这个值栈溢出不会用到),最后是被调用者的局部变量(一般按照源代码中声明的顺序从上往下排列,即从下往上依次压入,但可能会因为字对齐的原因留有碎片)。由于栈顶是低位地址,栈底是高位地址,当被调用者的局部变量定义的长度小于可写入的长度时,就会导致数据侵入高位内存,覆盖当前函数栈的返回地址。之后,若程序执行到当前函数栈返回时,就会跳转到我们控制的代码。
神经网络学习笔记(12) – 生成对抗网络
生成对抗网络Generative Adversarial Networks,简称(GANs)。其思想是用两个神经网络互相对抗,以生成一些“真实”的图像或视频。它的应用包括:AI艺术,人造图像,从2维图像生成3维图像,以及传统的分类、回归问题等。
两个对抗网络的分别为:生成网络(Generative network)和判别网络(Discriminative network)。
神经网络学习笔记(11) – 风格迁移
利用预训练的图像深度神经网络,可以实现美学上的风格迁移。这里需要两张输入图片,一张提供内容,另一张提供风格。
此时要训练的不是神经网络的参数(网络的参数将被固定住),而是目标图片。目标图片是二者的合成。要分别计算和最小化Content Loss和Style Loss。
神经网络学习笔记(10) – 迁移学习
迁移学习是指重用预先训练好的神经网络,固定那些低层(靠近输入)的权值,而训练高层(靠近输出)的权值,以解决类似的问题。这意味着无需自己重建网络的结构,并能节省训练的时间。至于何为类似的问题没有精确的说法,如图像识别问题、文本翻译问题可分别自成一类。比如,一个用来翻译英语到法语的模型,可以重用于印度语到西班牙语的翻译模型,尽管印度语到西班牙语的训练数据远不如英语到法语的。
神经网络学习笔记(9)- 卷积神经网络结构
由于一张图片的每个像素都是图片的一个特征,若按照最简单的结构,每一层的结点代表一个像素,再进行全连接,就会发生参数爆炸的现象。设想一个100×100的图像,共有10000个像素。每层就有10000个神经元。两层之间的全连接个数就是10000×10000。也就意味着有1亿个参数要训练!
另一方面,视觉在接收信息时,也是以2维团状来感知的。不会一个接一个像素地去看。其中有相当的冗余信息。
神经网络学习笔记(8)- 图像预处理
CNN(卷积神经网络)主要用于图像的训练。在介绍CNN之前,首先面临的问题是,如何来表示图像,以及有哪些预处理操作,能帮助更有效地进行CNN训练。
图像的Tensor表示
一张图可以表示为一个像素矩阵。我们知道计算机表示彩色图像的三原色:RGB,代表红、绿、蓝三个通道。它们的值域都为0~255。任何颜色都可以表示为这三个通道的组合。如(255,0,0)表示为纯红,(0,255,0)表示为纯绿。
通常,在训练CNN前,需要把这三个通道的值映射到-1~1的区域,以便能更高效地进行训练。
有时,色彩的信息并不重要,为了简化模型,则只需要一个灰度通道,即每个像素均对应一个0~1的值。
因此,一张2维图像,可以用3维的Tensor来表示。图像的长宽分别占2维,最后一维是颜色通道。灰度图像的第3维长度为1,彩色图像的第3维长度为3。
神经网络学习笔记(7) – 分类问题
对于分类问题,输入的样本或特征维度与线性回归问题没有差异,但输出值不再是一个数,而是一个数组,这个数组的每个元素对应于该样本被归于每个目标类型的概率。当预测时,概率高的那个类别,作为模型预测的结果。
我们知道,在每次事件中,概率模型要求:
1)样本被归于每个类别的概率都为0到1之间的实数
2)归于各个类别的概率总值为1
设想我们已构建了一组神经网络,他有隐藏层,有线性和非线性计算,也可能有Dropout。我们期望的输出的节点数即为类别数,每个节点的值对应于样本被分为该类别的概率。但经过神经网络计算后的值并不符合概率模型要求的2个条件。
为此,需要有一种方法,将任意域的一组数映射到满足这2个条件的空间上。SoftMax函数的作用就是如此。
神经网络学习笔记(6) - 从训练到评价
训练集与测试集的划分
和其他机器学习问题一样,要评价模型,就要先将原始训练数据划分为训练集和测试集,用训练集训练模型,再用测试集来评价。假设原始数据data是Pandas DataFrame,columns是一个特征列名构成的数组,target是结果列名构成的数组。可以用sklearn的train_test_split函数直接生成训练集和测试集。
features = data[columns]
target = data[targets]
from sklearn.model_selection import train_test_split
X_train, x_test, Y_train, y_test = train_test_split(features,target,test_size=0.2)
神经网络学习笔记(5) – Pytorch深度神经网络计算框架
PyTorch优化器
PyTorch将梯度计算的算法包装成优化器。优化器就是执行迭代更新待训练参数的一个对象。它的使用方式如下:
- 构造优化器,最简单的是传入所有待训练的参数。如果要给某些参数单独设置选项,就需传入一个参数字典。
- 调用backward()计算梯度
- 调用optimizer.step()更新参数值
详细例子可见官网。