栈溢出
原理
函数栈的结构如图。
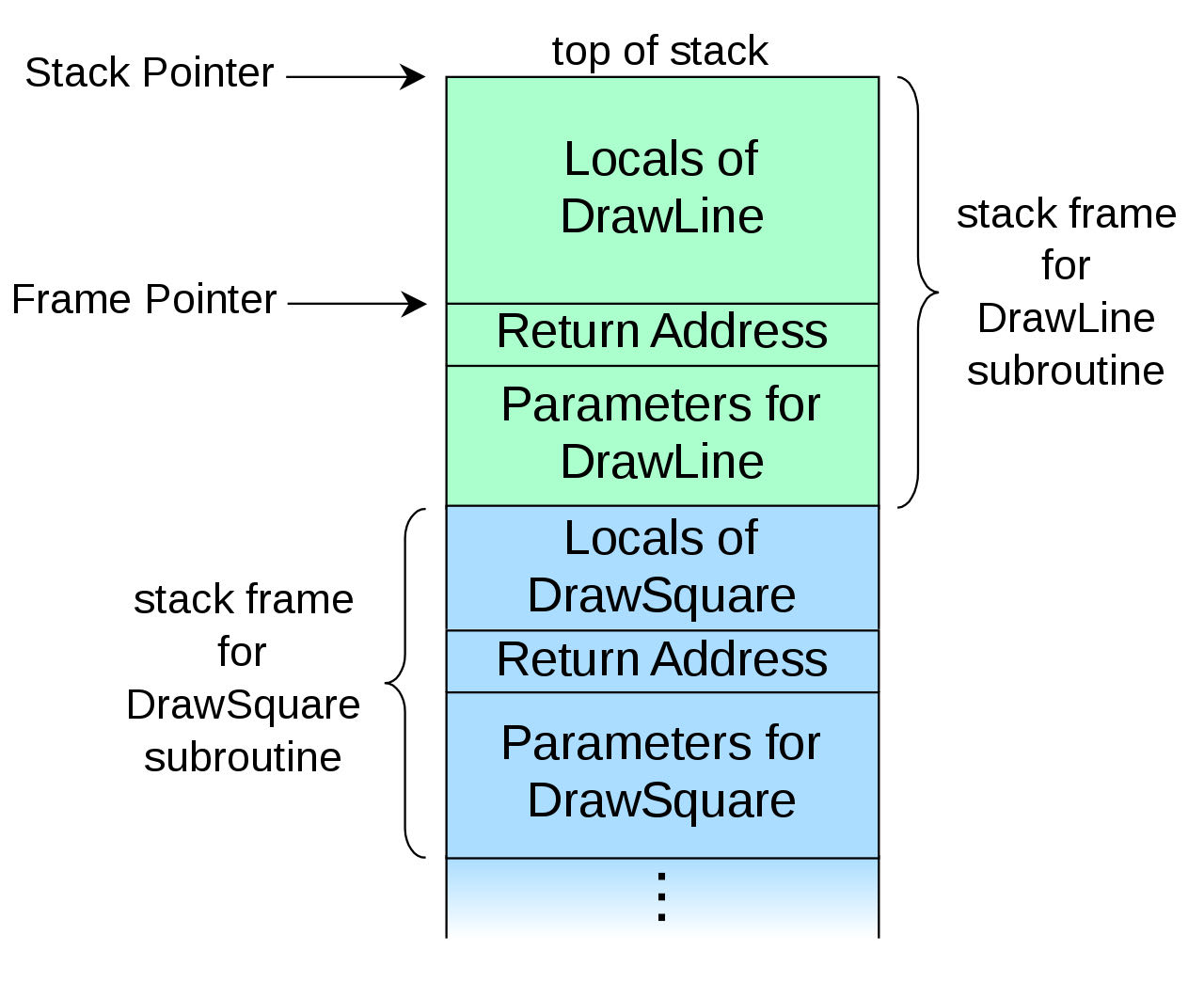
假设函数DrawSquare()调用了函数DrawLine(),被调用的栈就会建在调用方的栈的上方。整个栈往上生长。首先压入的是调用方传入的参数,然后是被调用者执行完后的返回地址,紧跟其后是图中未画出的8位的saved %ebp(32位和64位保存的方式不同,但都是8位,这个值栈溢出不会用到),最后是被调用者的局部变量(一般按照源代码中声明的顺序从上往下排列,即从下往上依次压入,但可能会因为字对齐的原因留有碎片)。由于栈顶是低位地址,栈底是高位地址,当被调用者的局部变量定义的长度小于可写入的长度时,就会导致数据侵入高位内存,覆盖当前函数栈的返回地址。之后,若程序执行到当前函数栈返回时,就会跳转到我们控制的代码。
如果返回地址被改写为call
工具
静态分析
file命令和pwn checksec命令
ghidra
动态分析
gef(加强版的gdb)
防御与绕过
程序做了哪些防御可通过file命令和pwn checksec命令来查看。分为以下几种。
NX(无执行权限)
代码段级别的执行权限的禁止。没有有效的绕过方法,只能把shell code写到可执行的代码段。
ASLR和PIE
ASLR全称是Address space layout randomization,是操作系统层面的技术,使其在运行时的段基址随机化。
PIE是二机制文件编译时的技术,允许其运行时可以被地址随机化。
PIE是ASLR的前提。如果二机制文件没有启用PIE,那么仅它的stack,heap和动态链接库会被随机化。
随机化的段地址起始可在gef中使用vmap命令查看各代码段起止进行确认。
gef➤ vmmap
Start End Offset Perm Path
0x0000000000400000 0x0000000000403000 0x0000000000000000 r-x /tmp/try
0x0000000000403000 0x0000000000404000 0x0000000000002000 r-x /tmp/try
0x0000000000404000 0x0000000000405000 0x0000000000003000 rwx /tmp/try
0x00007ffff7dcb000 0x00007ffff7fac000 0x0000000000000000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rwx /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rwx
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7ffc000 0x0000000000000000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rwx /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rwx
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rwx [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
虽然在动态分析时能看到真实地址,但当攻击者想要使用某些代码中的变量或函数来写exploit时就会因无法固定地址而失败。
然而每个变量或函数的地址,基于其所属的段基址的偏移量是不变的。因此绕过方法是需要泄露该代码段中某个变量的运行时地址,根据偏移量相同原则,就能得出任何其他位于该代码段的变量的地址。
RELRO(Relocation Read-Only)
Partial RELRO是GCC的缺省模式,对攻击没有很大影响。Full RELRO会把GOT设为只读。此时就无法覆盖GOT里的地址。GOT和动态链接库有关,下文会提及。
Stack Canary
在每次运行时,会在栈中(通常靠近下方)设置一个随机数哨兵。在函数运行结束前会再次检查这个随机数是否改变,若改变的话就中断程序。通常这个随机数的最后一个字节是00。
有两种绕过方法。
第一种依然是信息泄露,即读取这个随机数再在栈溢出攻击时在对应的地址补上这个数。
第二种是穷举法。若Stack Canary设置在程序fork的子进程,这个随机数在各个子进程是不变的。只要不断fork子进程,就能找出不crash的那个对应的随机数。
ROP攻击
综上的防御措施,针对前2种,又导向了新的破解思路。
由于某些段没有执行权限,攻击者要么去寻找那些既可以写又可以执行的段来写入自己的shell code,要么就地取材,利用现存的代码可执行段中的片段,通过组合来拼凑执行exploit。后者的那些代码片段就是所谓的Gadget。
而这个搭积木的实现过程,就是ROP chain。
攻击原理
ROP的全称是Return-oriented programming。当stack上没有执行权限时,利用汇编的RET = POP EIP的本质,精心在stack上写入Gadget的地址和相关数据,就能就地取材执行攻击者想要的操作。将其依次追加到stack,通过不停RET,依次执行。这就是ROP chain。最后组装成具有危害性的payload。
这里举一个采用ROP执行system call的例子。
查找调用方法
已知若要执行/bin/sh,可还原为写入各寄存器(或内存)相应的值,最后执行system call本身的指令。参阅Linux system call可知,执行system call(x64)时对寄存器具体要求为:
rax: 0x3b (系统调用类型为sys_execve)
rdi: ptr to “/bin/sh” (执行的文件名)
rsi: 0x0 (无需参数)
rdx: 0x0 (无需环境变量)
搜索Gadget
为了完成上述目标,首先查找binary中用于写入寄存器或内存的指令。使用pop指令可以写入寄存器;对于内存中的值,应先写入寄存器,然后用mov指令写入内存。
目前比较成熟的开源工具ROPgadget和one_gadget分别用于在二进制文件和libc中寻找可用的Gadget。
示例
python ROPgadget.py --binary crackme | grep "pop rax ; ret"
python ROPgadget.py --binary crackme | grep "mov" | less
python ROPgadget.py --binary crackme | grep ": syscall"
编写思路
从当前栈的返回地址开始写,除了最后的每条Gadget必须以RET结尾。由于RET等价于将POP EIP。因此如果一条ROP语句在执行过程中(包括在中途调用的其他函数中)有额外的POP,那在该语句后要给栈补足相应的空间(PUSH的话也需调整)。
汇编伪代码如下:
写内存 Write “/bin/sh” to 0x6c1000 (假设内存地址0x6c1000有rw权限,可通过vmap后动态调试找到空白区。或写入bss段的空区域,bss段地址不会动态变化)。可分解为先写入寄存器,再用mov指令把寄存器的数据写入内存地址。
pop rax, 0x6c1000 ; ret
pop rdx, "/bin/sh\x00" ; ret
mov qword ptr [rax], rdx ; ret
写入各寄存器
pop rax, 0x3b ; ret
pop rdi, 0x6c1000 ; ret
pop rsi, 0x0 ; ret
pop rdx, 0x0 ; ret
栈中实际写入的数据
上述伪汇编的涵义,是准备内存和寄存器的值,最后再加上执行系统调用的Gadget,就完成了。我们从return address开始如下写入Stack:
| Return Address → | ptr to gadget “pop rax; ret” |
|---|---|
| 0x6c1000 | |
| ptr to gadget “pop rdx; ret” | |
| “/bin/sh” in hex | 0x0068732f6e69622f |
| ptr to gadget “mov qword ptr [rax], rdx ; ret” | |
| ptr to gadget “pop rax; ret” | |
| 0x3b | |
| ptr to gadget “pop rdi; ret” | |
| 0x6c1000 | |
| ptr to gadget “pop rsi; ret” | |
| 0x0 | |
| ptr to gadget “pop rdx; ret” | |
| 0x0 | |
| ptr to gadget “syscall” |
当前函数栈返回时,就会执行ROP chain,最终执行了/bin/sh这个程序。
动态链接库
有时候,Gadget在binary文件中很难找到,此时可以考虑从动态链接库(如libc)里找。这就需要了解一下主程序是如何访问动态链接库的。
在程序内部有被称为PLT和GOT的数据结构。对于动态链接的函数,调用时先调用PLT里的函数地址。从那里跳往GOT Entry表中所指向的真实地址。
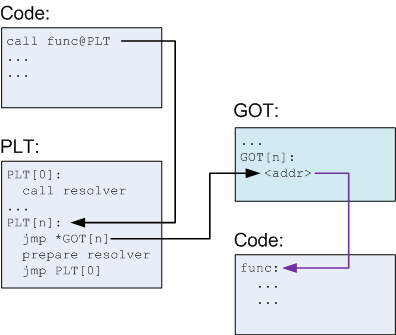
PLT和GOT都在binary段。libc函数的真实地址在GOT表的
在写payload时,若要调用libc函数,可直接使用PLT地址。但若要使用libc中的Gadget,为了绕过PIE,需要leak
获取原始地址
作为例子,我们要获取libc函数puts在GOT的原始地址。
这可通过pwn获取。同时也能获取PLT的原始地址。
from pwn import *
elf = ELF('svc')
print "plt address: " + hex(elf.symbols['puts'])
print "got address: " + hex(elf.got['puts'])
另一种方法是通过objump获取
objdump -D <binary>| grep puts //For PLT
objdump -R <binary> | grep puts //For GOT Entry
获取运行时地址
- 确认libc的版本。这一步可以使用gdb下的vmmap命令看到
- Leak libc函数的地址。可以使用系统的write()或puts()打印出来。类似前面的ROP示例,依然是准备寄存器后,执行write或puts的真实PLT地址(这需要动态分析)。这两个函数的执行规范如下。
write() InfoLeak
rdi: 0x1 Specify stdout file handle
rsi: ptr to the GOT entry
rdx: value >=8
puts() InfoLeak
rdi: ptr to the GOT entry
攻击流程总结
- 发现栈溢出漏洞
- 定位通过外部输入来溢出变量的函数,如get,scanf等
- 记录导致该函数栈溢出漏洞的变量到返回地址的偏移量
- 若中途有Stack Canary,则需要先解决之
- 构造输入payload,填充(包括Stack Canary)至偏移量。
- 若Stack可以执行,则可直接填充shell code,并把返回地址写成漏洞变量的起始地址
- 反之,若Stack不可执行,或不够用来装填shell code,可以到达返回地址后,继续开始写ROP chain
- 当采用了动态随机地址的技术时,需Leak地址,算出偏移量。
gdb动态分析技巧
设断点在用户输入的系统调用(如get)的后一句。
使用命令i f : 查看当前stackframe的信息(包括rip保存了返回地址)
使用命令search-pattern <输入数据> :查询用户输入数据的内存地址
让程序强制中断(Ctrl+C)后用bt来查找call stack地址,结合ghidra查看disassemble的源码。
进入子线程: set follow-fork-mode child (使用show follow-fork mode查看是否设置成功)
gef中可使用以下方法查看启用PIE后的动态地址,然后在该地址设断点:
disas <function name>
pie b *<断点地址>
pie run