神经网络学习笔记(11) – 风格迁移
利用预训练的图像深度神经网络,可以实现美学上的风格迁移。这里需要两张输入图片,一张提供内容,另一张提供风格。
此时要训练的不是神经网络的参数(网络的参数将被固定住),而是目标图片。目标图片是二者的合成。要分别计算和最小化Content Loss和Style Loss。
下面是风格迁移的架构: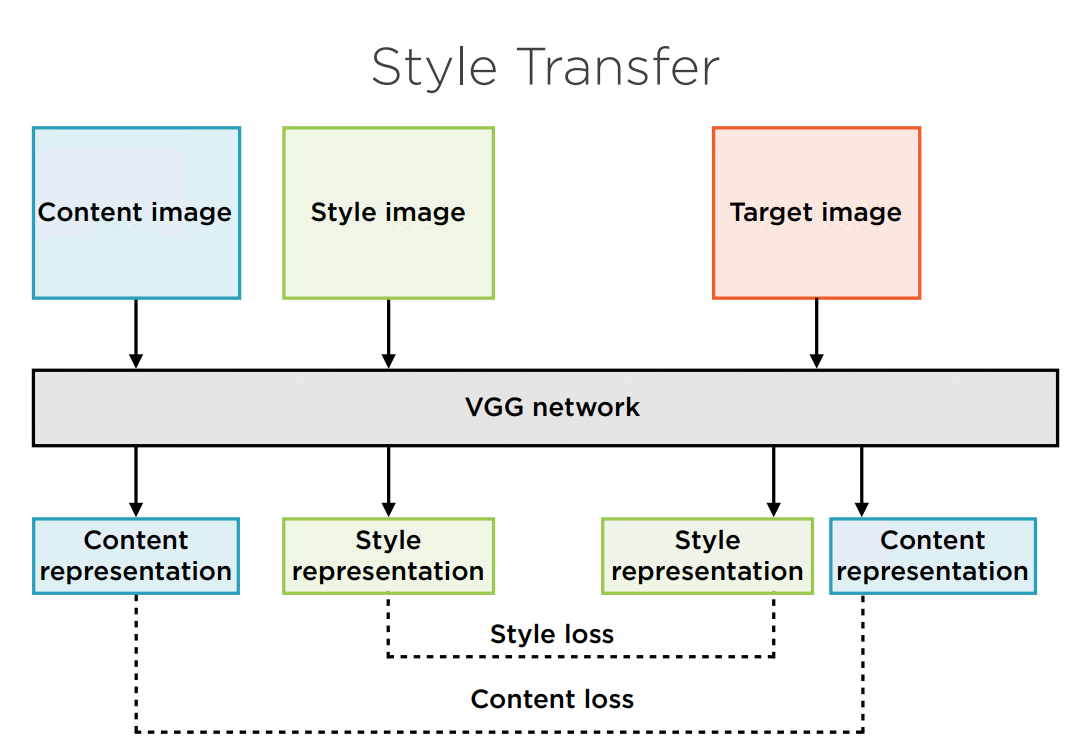
这里采用VGG19作为预训练的CNN网络。
内容图像经过网络生成了内容表征。
风格图像经过网络生成了风格表征。
另有一张图片(可以是内容图像的拷贝),经过网络生成了其对应的内容表征和风格表征,他们分别与2个原始图像的表征计算Loss,并反向传播调整目标图像的像素。
如何表征内容和风格?
内容表征直接采用CNN的Feature Map(通过卷积层的结果)。经验上,越是靠近输入的层越表征图像的细节,越靠后越能体现整体和语义。可以选择靠中后层的Feature Map来作为内容表征。使用MSE loss来衡量原图中后层的Feature Map和目标图中后层的Feature Map之间的Loss。
至于风格的表征有点复杂,可先将生成的Feature Map扁平化。扁平化后的Feature Map将保留风格信息,而失去了结构信息。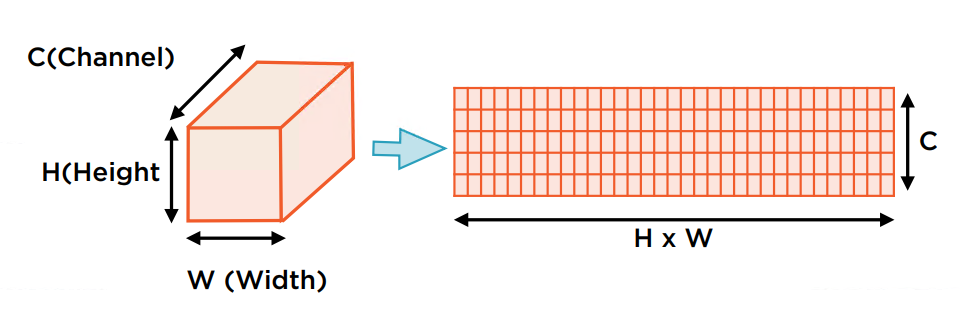
然后将此向量与其转置向量点积,得到Gram Matrix。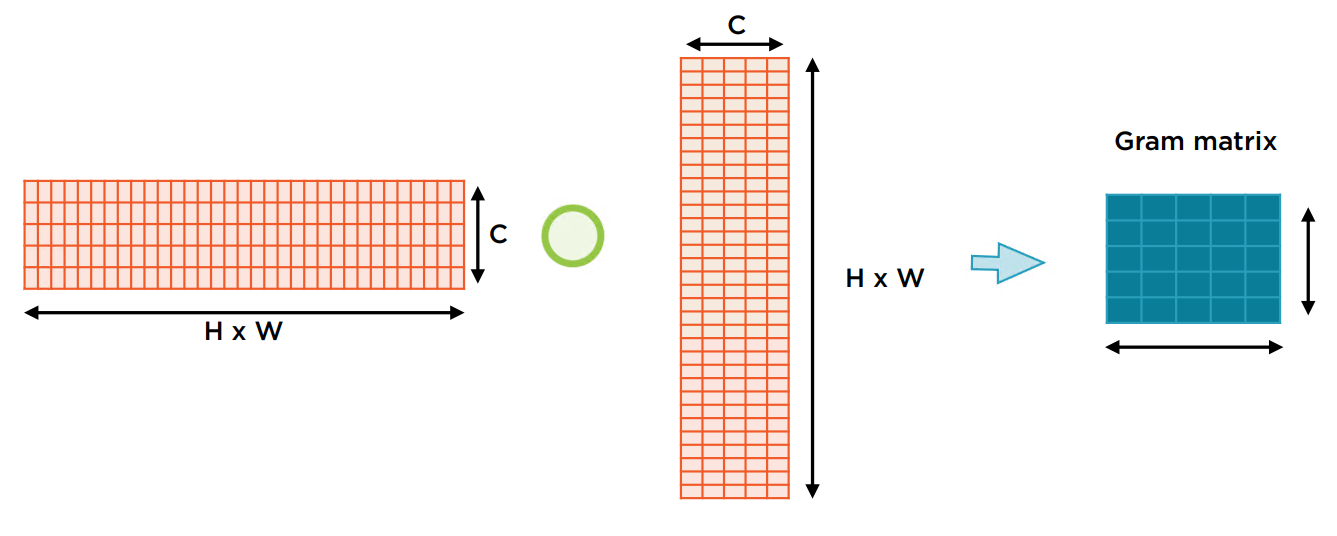
与内容表征相反,越靠近输入的层能更好反应图像的风格,但最好将靠前的多层的Feature Map都考虑进去,使用权重来反映各层的影响度。再使用MSE loss来衡量基于Gram Matrix的Style Loss。
总结一下。总体的Loss来自两方面,内容方面选取一个中后层的Feature Map,风格方面选取按权重递减的每一层的Feature Map生成各自的Gram Matrix。将这些Loss线性相加作为最终的Loss。
以下是Pytorch代码实现的风格迁移示例程序(使用SqueezeNet)。这里选取了conv7_1层来生成内容表征的Feature Map。前8层按不同权重生成风格表征的Gram Matrix。但这些选择都是非常经验性的,可以反复调试。这里的例子使用了一只猫提供内容与梵高的《星空》提供风格合成的结果。
import numpy as np
from PIL import Image
import torch
import torch.optim as optim
from torchvision import models
from torchvision import transforms as tf
import torch.nn.functional as F
squeezenet = models.squeezenet1_0(pretrained=True).features
for param in squeezenet.parameters():
param.requires_grad_(False)
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
squeezenet.to(device)
'''
观察网络定义,关注卷基层Conv2d
Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(3): Fire(
(squeeze): Conv2d(96, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(4): Fire(
(squeeze): Conv2d(128, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(5): Fire(
(squeeze): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(6): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(7): Fire(
(squeeze): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(8): Fire(
(squeeze): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(9): Fire(
(squeeze): Conv2d(384, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(10): Fire(
(squeeze): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
(11): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(12): Fire(
(squeeze): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace=True)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace=True)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace=True)
)
)
'''
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
def transformation(img):
tasks = tf.Compose([tf.Resize(256),
tf.ToTensor(),
tf.Normalize(mean, std)])
img = tasks(img)
img = img.unsqueeze(0)#为适应API,新增batch维度
return img
content_img = Image.open("cat.jpg").convert('RGB')
style_img = Image.open("starry_night.jpg").convert('RGB')
content_img = transformation(content_img).to(device) #torch.Size([1, 3, 256, 256])
style_img = transformation(style_img).to(device) #torch.Size([1, 3, 256, 320])
#根据该网络的结构定义,选取每个靠近输入的卷积层,用来提取Feature Map。
LAYERS_OF_INTEREST = {'0': 'conv1_1',
'3': 'conv2_1',
'4': 'conv3_1',
'5': 'conv4_1',
'6': 'conv5_1',
'7': 'conv6_1',
'8': 'conv7_1',
'9': 'conv8_1'}
def apply_model_and_extract_features(image, model):
x = image
features = {}
for name, layer in model._modules.items():
x = layer(x)#生成改层的Feature Map
if name in LAYERS_OF_INTEREST:
features[LAYERS_OF_INTEREST[name]] = x
return features
content_img_features = apply_model_and_extract_features(content_img, squeezenet)
style_img_features = apply_model_and_extract_features(style_img, squeezenet)
#计算Gram Matrix
def calculate_gram_matrix(tensor):
_, channels, height, width = tensor.size()
tensor = tensor.view(channels, height * width)#扁平化
gram_matrix = torch.mm(tensor, tensor.t())
gram_matrix = gram_matrix.div(channels * height * width)#标准化
return gram_matrix
style_features_gram_matrix = {layer: calculate_gram_matrix(style_img_features[layer]) for layer in
style_img_features}
#给每层的Feature Map设定一个风格权重。由高到低。供Style的Feature Maps用。但conv7_1层上Feature Map用来计算内容Loss,可以权重再低点。
weights = {'conv1_1': 1.0, 'conv2_1': 0.8, 'conv3_1': 0.65,
'conv4_1': 0.5, 'conv5_1': 0.45, 'conv6_1': 0.3,
'conv7_1': 0.1, 'conv8_1': 0.15}
target = content_img.clone().requires_grad_(True).to(device)#目标图像先从原始的内容图像克隆
optimizer = optim.Adam([target], lr=0.003)#目标是生成图像。因此待优化的是target图像,而非神经网络参数。
for i in range(1, 2000):
target_features = apply_model_and_extract_features(target, squeezenet)
#只选conv7_1作为Content Feature,计算Loss
content_loss = F.mse_loss (target_features['conv7_1'], content_img_features['conv7_1'])
style_loss = 0
for layer in weights:
target_feature = target_features[layer]
target_gram_matrix = calculate_gram_matrix(target_feature)
style_gram_matrix = style_features_gram_matrix[layer]
layer_loss = F.mse_loss (target_gram_matrix, style_gram_matrix)
layer_loss *= weights[layer]
_, channels, height, width = target_feature.shape
style_loss += layer_loss
total_loss = 1000000 * style_loss + content_loss
if i % 50 == 0:
print ('Epoch {}:, Style Loss : {:4f}, Content Loss : {:4f}'.format( i, style_loss, content_loss))
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
#此时target的Tensor再转换为图像,即为生成的目标图像了。
def tensor_to_image(tensor):
image = tensor.clone().detach()
image = image.cpu().numpy().squeeze()
image = image.transpose(1, 2, 0)
image *= np.array(std) + np.array(mean)
image = image.clip(0, 1)
return image
target_image = tensor_to_image(target)