Unsafe unlink()
何为Unlink()
Unlink()是free()调用中的一步。当free某个chunk时,程序会查看其上一个chunk是否也是free,如果是,就会把上一个chunk从bin的双向链表上移除(这就是unlink),并与当前free的chunk合并。这里要注意,如果上一个chunk在fastbin或tcache,是不会发生unlink和合并的。这是因为他们被设计成非常高效的缓存,避免诸如合并的多余操作。
从结论来说,这个漏洞能够使我们写任意地址的数据。
自指指针数组与写任意地址
先抛开heap,来构造这样一种场景。
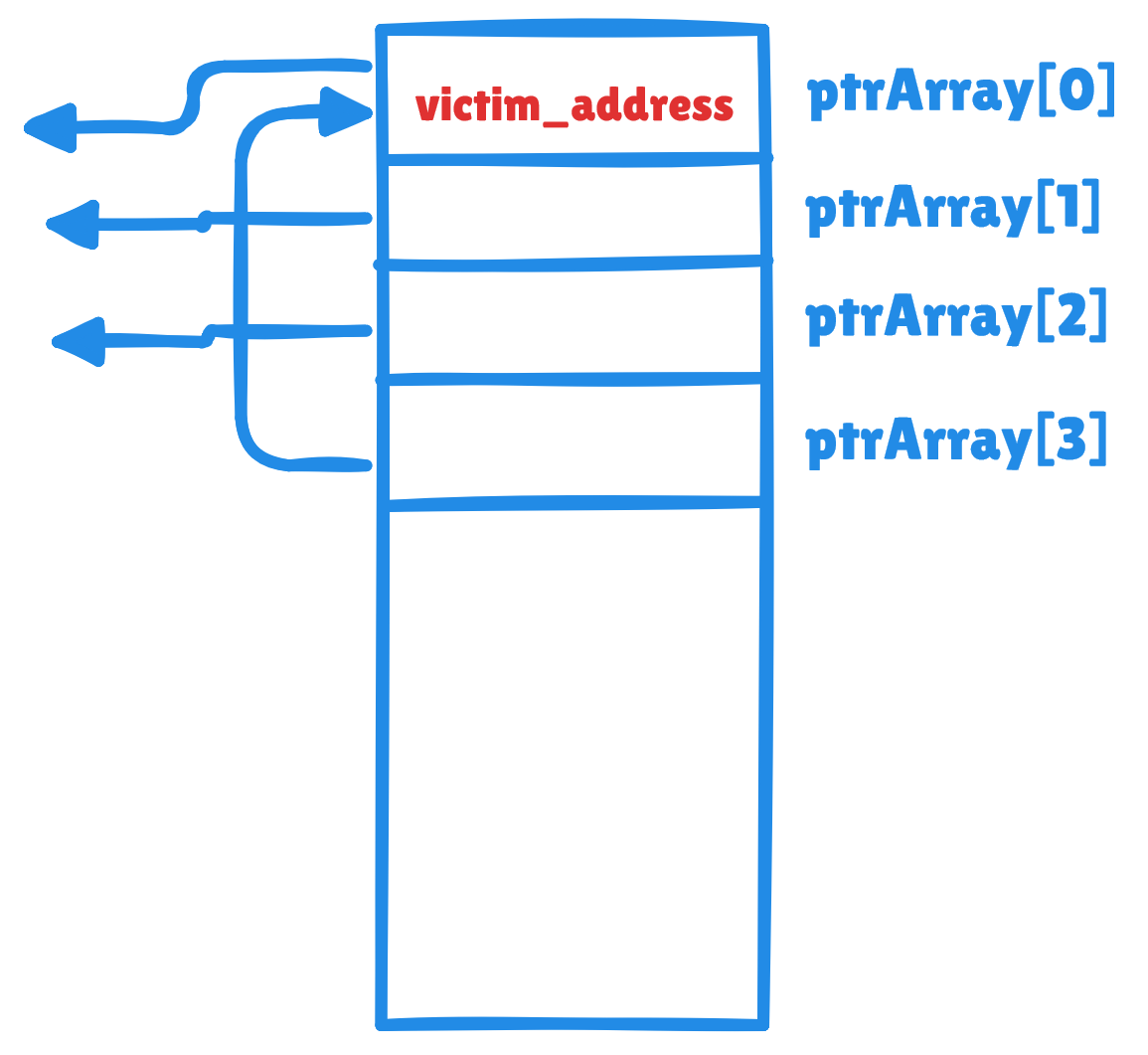
假设我们能往一个指针数组ptrArray的每个成员所指向的地址写数据(这种场景并不罕见,比如一个成员都是字符串类型的数组),但其中一个成员是这个指针数组自身(或临近的地址),那我们就有机会覆盖ptrArray的任意其他成员,比如ptrArray[3],将其覆盖为一个任意地址:ptrArray[3] = <任意地址>。再往ptrArray[3]所指向的地址写数据,就是往<任意地址>写数据了。
//假定我们可以调用以下函数,往ptrArray[index]处的地址写入data
write(ptrArray, index, data)
//执行以下语句后ptrArray[0] = victim_address
write(ptrArray, 3, victim_address)
//执行以下语句后*victim_address = data
write(ptryArray, 0, malicious_data)
这里关键的一步在于,指针数组的某个成员指向这个数组自身。而Unlink()漏洞就能达成这一点。
漏洞效果
这个漏洞的效果在于,假设:
- 我们要free的chunk记为A
- 他的上一个chunk(在heap内存空间中的邻接上一个,通过头地址减去current chunk size得出上一个chunk的头地址)记为B
- 我们能控制一个其成员指向B的指针数组ptrArray(同时有能力调用上述的write(ptrArray, index, data)函数),假设指向B的成员为ptrArray[i]
- 假设ptrArray的每个指针成员的大小为8个字节,那么该漏洞触发后,我们可以使ptrArray[i]指向&ptrArray[i] - 0x18,也即ptrArray[i]指向ptrArray[i-3]的地址
漏洞原理
漏洞的实现方法是堆溢出。如果我们能够写B的数据,而程序没有检查边界,就能溢出而改写A的头部元数据,让A以为他的上一个chunk已释放,同时把B的状态改成freed,从而启动合并程序。如此触发Unlink后,B会从程序以为的“双向链表”上移除,具体来说B的前继Chunk的后继会指向B的后继Chunk,而B的后继Chunk的前继会指向B的前继Chunk。而源代码中对于前继和后继的判定规则非常简单,前继指针即为chunk头指针向后+2的偏移量,后继指针即为chunk头指针向后+3的偏移量。
回顾一下chunk的数据结构如下:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk fd; /* double links -- used only if this chunk is free. */
struct malloc_chunk bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk fd_nextsize; /* double links -- used only if this chunk is free. */
struct malloc_chunk bk_nextsize;
};
typedef struct malloc_chunk* mchunkptr;
因此,我们在可控制的内存区域(实际上就是ptrArray附近)构造一个非常简单的双向链表上的2个节点(记为C,D)。将B的前继写为C,B的后继写为D,巧妙安排C和D的位置,使C的后继和D的前继公用同一块地址空间(设这个地址为f)。
代入上述操作重述为:
经过Unlink后,
B的前继Chunk的后继会指向B的后继Chunk,而B的后继Chunk的前继会指向B的前继Chunk
-> C的后继会指向D,D的前继会指向C
-> f会指向D,f会指向C (这里代码先后执行,后者覆盖前者)
-> f会指向C
进一步地,如果把C的头指针记为ptrC,它后继指针的地址即为ptrC+3。故f=ptrC+3。得出ptrC+3指向C。换句话说,我们能让位于ptrArray附近的ptrC+3指向同样位于ptrArray附近的C,实现了指针数组的成员指向指针数组自身。
绕过检查
源代码为了防止这种漏洞,在unlink之前,做了一些检查,因此需要绕过他们。
- 确保B的前继的后继是B;确保B的后继的前继是B。这在上述构造中已有考量,他们共享同一块地址空间f,只需令其指向B即可。
- 确保A的previous chunk size等于B的chunk size。通过溢出B的数据,可以修改A的这块数据。
- 确保A的Previous chunk in use(P标志位)为0。通过溢出B的数据,可以修改A的这块数据。
- 由于largebin里的chunk还会检查fd_nextsize和bk_nextsize。为了避免更多检查,将B的fd_nextsize也清零。
实例
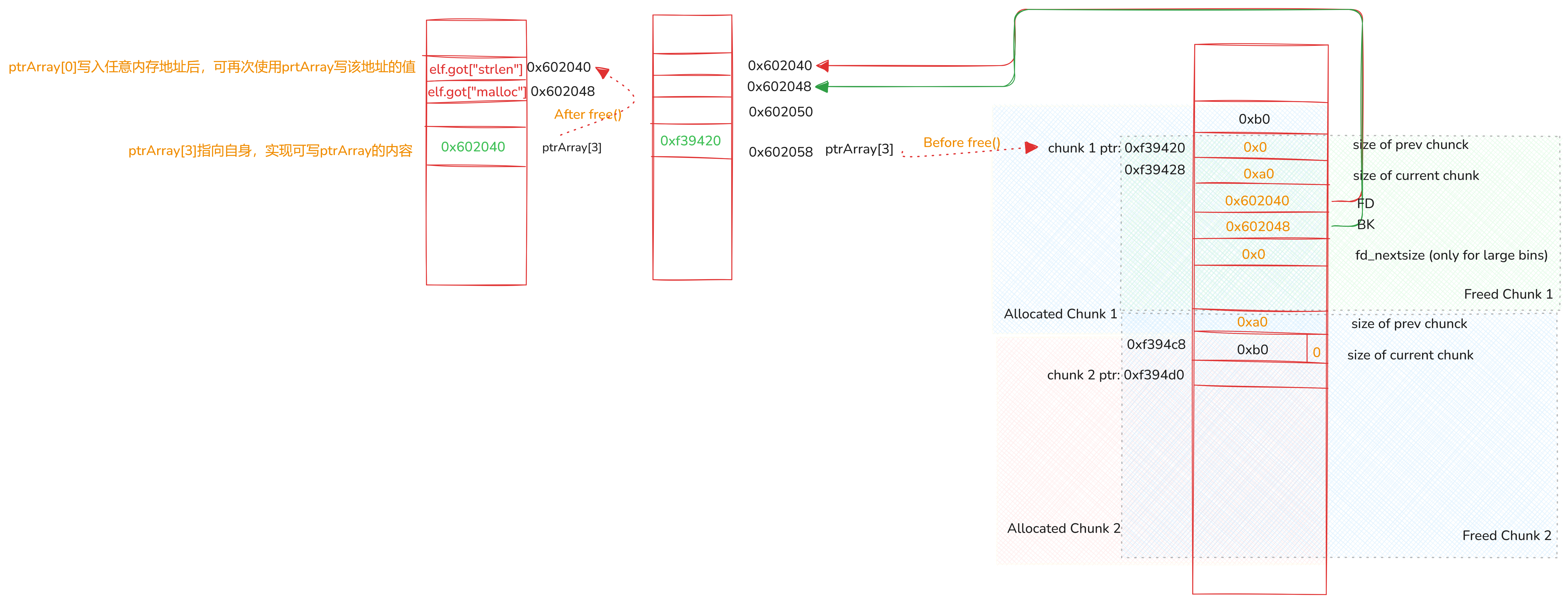
在上述例子中,位于0x602058的ptrArray[3]原本指向chunk 1的数据区。通过溢出可以依次写入chunk 1和chunk 2头部,一方面把chunk 2上方的空间伪造成一个释放后的chunk,另一方面满足程序需要的所有检查条件。伪造的chunk的前继和后继被安置于ptrArray[0]和ptrArray[1],使得前者的后继(+3偏移)和后者的前继(+2偏移)都是位于ptrArray[3]的chunk 1 ptr。
Unlink()触发后,ptrArray[3]指向了ptrArray[0]。此时写ptrArray[3]指向的内容就是写ptrArray自身。之后就能改写任意标准函数的GOT地址了。