神经网络学习笔记(15) – Seq2Seq与文本翻译
先前的RNN模型都是输入一个向量序列,输出单个向量。在翻译问题中,采用了输入一个向量序列,输出也是一个向量序列的模型。这个序列到序列的模型就是Seq2Seq。
作为准备工作,首先将文本的句子用Embedding的方式表示,然后做padding到一个该语言的最大序列长度。
使用2个RNN模型,一个作为Encoder,将原始语言映射到一种单一向量的“中间表示”,另一个作为Decoder,把这种中间表示再输出到目标语言。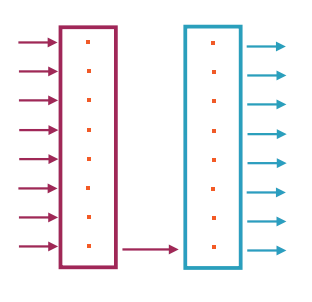
在训练阶段,需要大量现成的双语翻译对照文本。这里有一个叫做Teacher Forcing的技巧。在训练时不仅把原始语言的数据作为输入,由于目标语言的输出也是一个序列,可将目标语言的t-1的输入一同追加到用以预测t的输出上。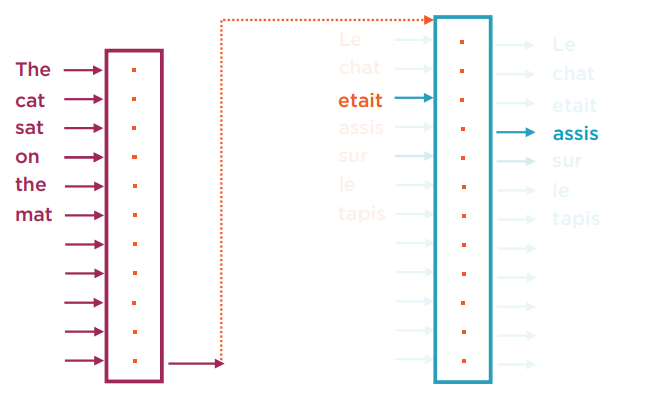
以下是一个基于该数据集的德语到英语的翻译模型。
为了简化,使用one-hot的方式来表达文本。
from io import open
import unicodedata
import string
import re
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
SOS_token = 0#开始符号
EOS_token = 1#结束符号
#构建one-hot的词汇表。
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
#将Unicode转换为小写的ASCII,并除去标点
def normalizeString(s):
s = s.lower().strip()
s = ''.join(
char for char in unicodedata.normalize('NFD', s)
if unicodedata.category(char) != 'Mn')
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
#读数据集,解析双语句子对
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
lines = open('datasets/data/%s-%s.txt' % (lang1, lang2), encoding='utf-8'). \
read().strip().split('\n')
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
#为简化,只训练最大10个单词,且英文版本是以下eng_prefixes开头的句子。
MAX_LENGTH = 10
eng_prefixes = ("i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re ")
def filterPairs(pairs):
return [p for p in pairs
if
len(p[0].split(' ')) < MAX_LENGTH and
len(p[1].split(' ')) < MAX_LENGTH and p[1].startswith(eng_prefixes)] #构建训练数据 def prepareData(lang1, lang2, reverse=False): input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse) print("Read %s sentence pairs" % len(pairs)) pairs = filterPairs(pairs) print("Trimmed to %s sentence pairs" % len(pairs)) for pair in pairs: input_lang.addSentence(pair[0]) output_lang.addSentence(pair[1]) print("Counted words:") print(input_lang.name, input_lang.n_words) print(output_lang.name, output_lang.n_words) return input_lang, output_lang, pairs input_lang, output_lang, pairs = prepareData('eng', 'deu', reverse=True) #将语句转换为用在词汇表中的index表示的Tensor def tensorFromSentence(lang, sentence): indexes = [lang.word2index[word] for word in sentence.split(' ')] indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long).view(-1, 1)#view(-1,1)表示为n行1列的形式 def tensorsFromPair(pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor) class EncoderRNN(nn.Module): def __init__(self, input_size, hidden_size): super(EncoderRNN, self).__init__() self.hidden_size = hidden_size self.embedding = nn.Embedding(input_size, hidden_size) self.gru = nn.GRU(hidden_size, hidden_size) def forward(self, input, hidden): #input size: [1] 即索引值 #after embedding, 在最后追加一维:[1, embedding_dim=hidden_size] #after view: [1, hidden_size] -> [1, 1, hidden_size]
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
#input size有3种情况
#1)初始值torch.tensor([[SOS_token]]) -> [1, 1]
#2)使用Teacher Forcing时,输入为上一个target_tensor的单词 -> [1]
#3)不适用Teacher Forcing时,表示预测的词汇索引的被squeeze后的0维Tensor -> []
#after embedding, 在最后追加一维embedding_dim=hidden_size
#after view,output统一转化为[1, 1, hidden_size]
#hidden size: 同样是[1, 1, hidden_size]
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
#self.gru为hidden_size -> hidden_size,固output还是[1, 1, hidden_size],output[0]为[1, hidden_size]
output, hidden = self.gru(output, hidden)
#self.out为hidden_size -> output_size,固output最终为 [1, output_size]
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size)
teacher_forcing_ratio = 0.5#50%几率使用Teacher Forcing,即目标语言的t-1的训练数据。否则,就用t-1的预测数据。
def train(input_tensor, target_tensor,
encoder, decoder,
encoder_optimizer, decoder_optimizer,
criterion):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0) #源语言句子Tensor的单词数
target_length = target_tensor.size(0)#目标语言句子Tensor的单词数
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
decoder_input = torch.tensor([[SOS_token]])
decoder_hidden = encoder_hidden #decoder的第一个序列的hidden输入等于encoder最后一个序列的hidden输出
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
for di in range(target_length):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di]
else:
for di in range(target_length):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden)
#decoder_output是长度为output_lang.n_words,即目标语言词汇长度的Tensor,其中每个词汇索引对应的值是概率。取概率最大的索引。
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
plot_losses = []
print_loss_total = 0
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size)
decoder1 = DecoderRNN(hidden_size, output_lang.n_words)
encoder_optimizer = optim.SGD(encoder1.parameters(), lr=0.01)
decoder_optimizer = optim.SGD(decoder1.parameters(), lr=0.01)
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(30000)]
criterion = nn.NLLLoss()#评价是基于每个序列上单词的输出,因为用one-hot表示,所以本质是分类问题。
for iter in range(1, 30001):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor,
encoder1, decoder1,
encoder_optimizer, decoder_optimizer,
criterion)
print_loss_total += loss
if iter % 1000 == 0:
print_loss_avg = print_loss_total / 100
print_loss_total = 0
print('iteration - %d loss - %.4f' % (iter, print_loss_avg))