神经网络学习笔记(14) – 非定长序列的RNN
在这个案例里,我们要预测某个名字是哪个国家的。名字是一个字母序列组成的字符串。以此为例介绍另一种非定长的序列的RNN实现。
为了简化问题,假定只考虑英文26个字母表示的名字。每个字母使用如下one-hot的向量表示。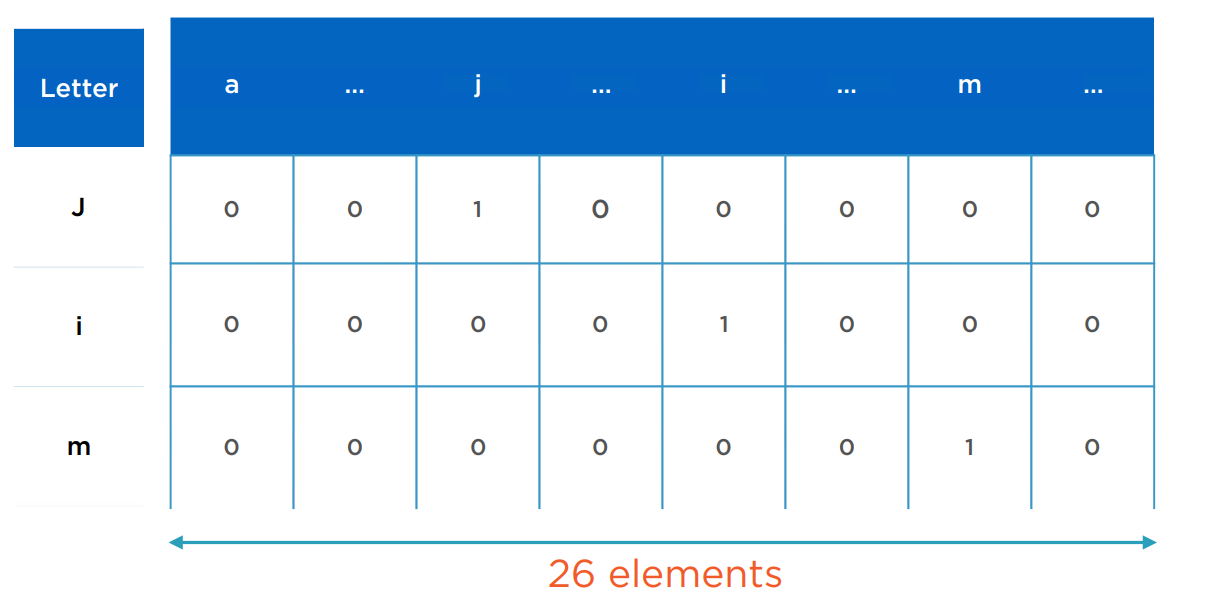
这里不用PyTorch内置的LSTM模型,而是直接把输入Tensor和隐Tensor连接合并,送到序列下一个节点的RNN层中。RNN的实现只采用了轻量的线性层和LogSoftmax。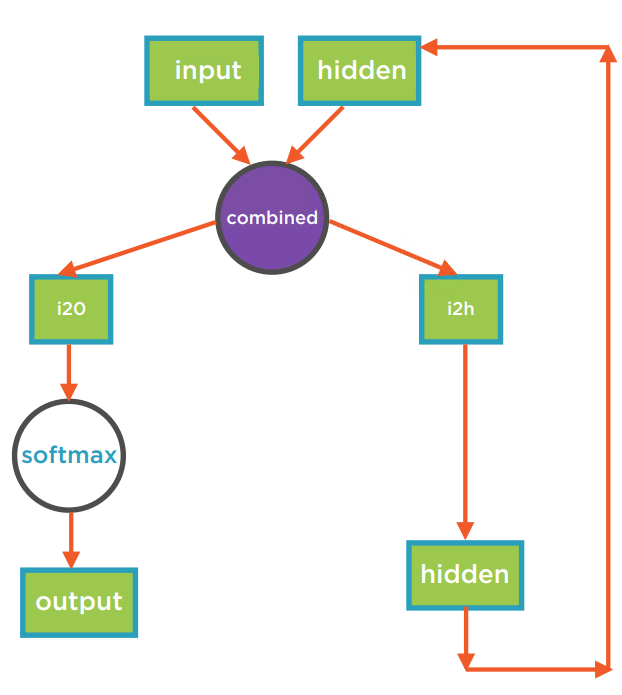
图中Input为单个字母,Tensor尺寸等于字母表的大小,因为每个字母都使用字母表大小的one-hot向量表示。Hidden Tensor的尺寸定为256。Combine Tensor为简单的连接操作的结果,尺寸变为2者之和。Combine通过2个层,一个输出为预测结果,另一个输出成为输入下一个序列的Hidden Tensor。因此这个过程支持对键入的每一个字母作一次预测,随着键入的字母串越长,预测得就越准确。
from io import open
import glob
import os
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'" #所有英文字母加上一些标点: abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
n_letters = len(all_letters) #n_letters = 57
language_names = {}
all_languages = []
#将一些特殊字符转换到普通ASCII字符(如É->E) https://stackoverflow.com/questions/517923/what-is-the-best-way-to-remove-accents-in-a-python-unicode-string/518232#518232
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
def findFiles(path):
return glob.glob(path)
total_names = 0
#在以下文件目录每个语言一个文本文件,包含该语言下的名字
for filename in findFiles('datasets/data/names/*.txt'):
language = os.path.splitext(os.path.basename(filename))[0]
all_languages.append(language)
read_names = open(filename, encoding='utf-8').read().strip().split('\n')
names = [unicodeToAscii(line) for line in read_names]
language_names[language] = names
total_names += len(names)
n_languages = len(all_languages) #n_languages = 18
print(language_names['Czech'][:5]) #['Abl', 'Adsit', 'Ajdrna', 'Alt', 'Antonowitsch']
import torch
#将字母转换为one-hot的Tensor
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)#额外的第0维,是因为PyTorch总是假定Tensor的第0维为batch维。
tensor[0][all_letters.find(letter)] = 1
return tensor
def nameToTensor(name):
tensor = torch.zeros(len(name), 1, n_letters)
for li, letter in enumerate(name):
tensor[li][0][all_letters.find(letter)] = 1
return tensor
mary_tensor = nameToTensor('Mary')#torch.Size([4, 1, 57])
#构建RNN
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
n_hidden = 256
rnn = RNN(n_letters, n_hidden, n_languages)
#简单测试
inp = letterToTensor('C')
hidden = torch.zeros(1, n_hidden)
output, next_hidden = rnn(inp, hidden)
print('output size =', output.size()) #torch.Size([1, 18])
print('next_hidden size =', next_hidden.size())#torch.Size([1, 256])
inp = nameToTensor('Charron')
hidden = torch.zeros(1, n_hidden)
output, next_hidden = rnn(inp[0], hidden)
#基于output的最大分量,输出可被理解的语言类别
def languageFromOutput(output):
_, top_i = output.topk(1)
language_i = top_i[0].item()
return all_languages[language_i], language_i
print(languageFromOutput(output))#('Vietnamese', 5)
import random
#训练数据准备。随机选择一个某语言文本中的某名字,并返回语言、名字、和对应的tensor
def randomTrainingExample():
random_language_index = random.randint(0, n_languages - 1)
language = all_languages[random_language_index]
random_language_names = language_names[language]
name = random_language_names[random.randint(0, len(random_language_names) - 1)]
language_tensor = torch.tensor([all_languages.index(language)], dtype=torch.long)
name_tensor = nameToTensor(name)
return language, name, language_tensor, name_tensor
#训练开始
criterion = nn.NLLLoss()
learning_rate = 0.005
def train(langauge_tensor, name_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(name_tensor.size()[0]):
output, hidden = rnn(name_tensor[i], hidden)
loss = criterion(output, langauge_tensor)
loss.backward()
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
n_iters = 200000
current_loss = 0
all_losses = []
for epoch in range(1, n_iters + 1):
language, name, language_tensor, name_tensor = randomTrainingExample()
output, loss = train(language_tensor, name_tensor)
current_loss += loss
if epoch % 5000 == 0:
guess, guess_i = languageFromOutput(output)
correct = '✓' if guess == language else '✗ (%s)' % language
print('%d %d%% %.4f %s / %s %s' % (epoch,
epoch / n_iters * 100,
loss,
name,
guess,
correct))
if epoch % 1000 == 0:
all_losses.append(current_loss / 1000)
current_loss = 0
#进行预测,返回概率最大的3种语言
n_predictions = 3
input_name = 'Batsakis'
with torch.no_grad():
name_tensor = nameToTensor(input_name)
hidden = rnn.initHidden()
for i in range(name_tensor.size()[0]):
output, hidden = rnn(name_tensor[i], hidden)
topv, topi = output.topk(n_predictions, 1, True)
for i in range(n_predictions):
value = topv[0][i].item()
language_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_languages[language_index]))