神经网络学习笔记(13)- 循环神经网络与自然语言处理
RNN(Recurrent Neural Network),即循环神经网络,适用于诸如
网络的结构
基于式子 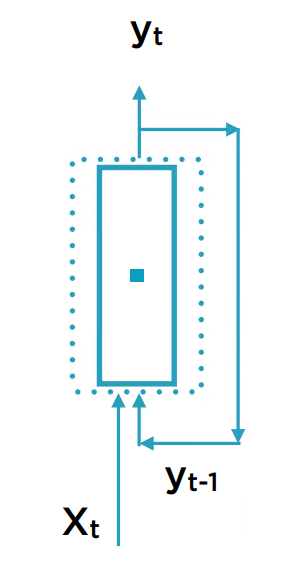
从时间t上展开,就是如下的结构: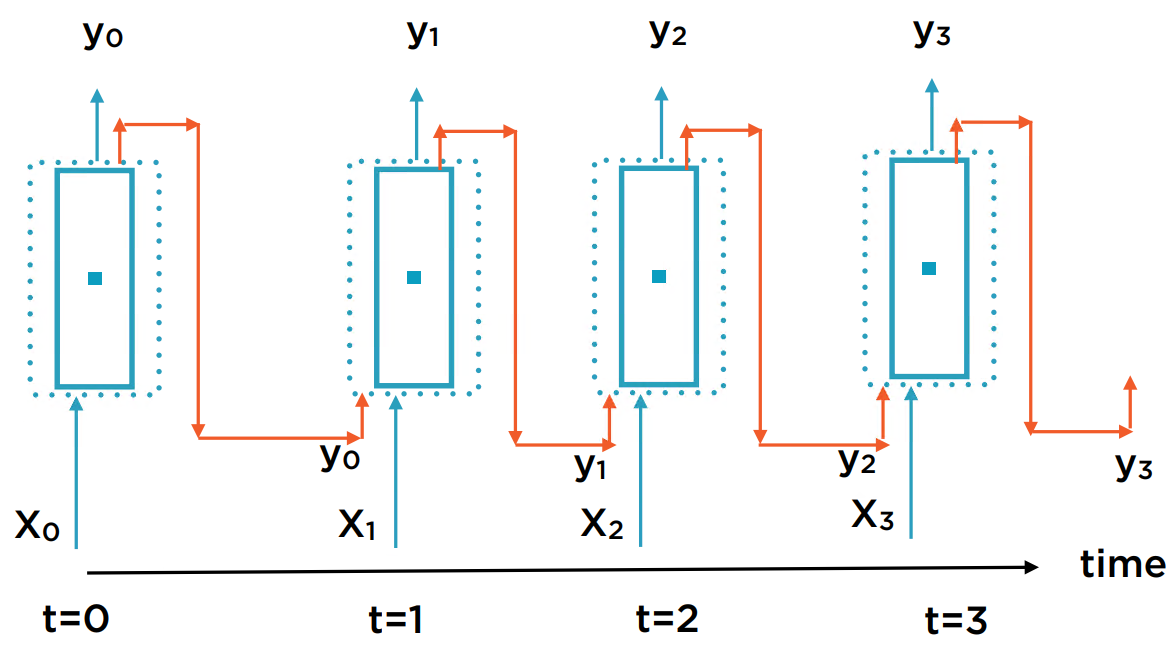
每个RNN单元的输入为一个向量:
将两个输入的权重分别记为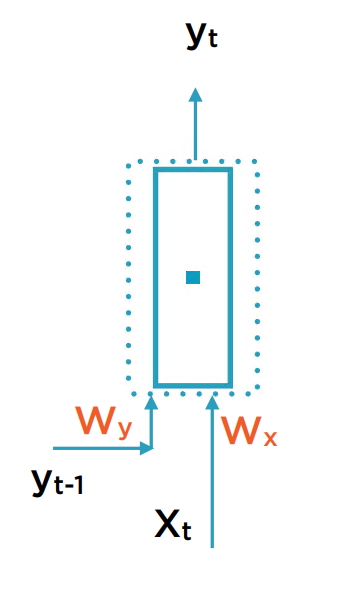
神经元的计算表达式为:
可以看到,
为解决此问题,首先想到的是将输入的序列截断。如预测股票价格时,假设明天的价格只依赖于上一周每天的价格。然而这种假设是否合理呢?如何兼顾长期状态的贡献?于是想到了给RNN单元引入额外的表示记忆状态输入量。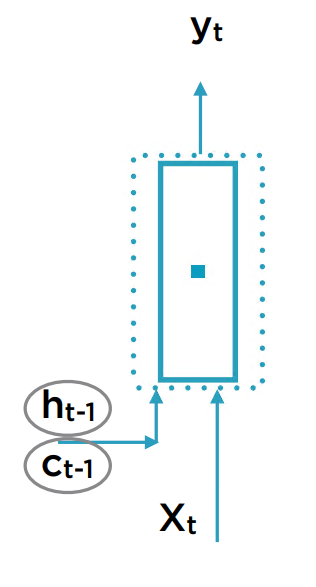
把长期状态记为C,短期状态记为h。
这种存储长期记忆的方法,能加快训练时间,“看”到更远的context。LSTM(Long/Short-Term Memory Cell)就实现了这种思想。
在一个LSTM单元中,输入为
从直观上,一个LSTM网络如下图所示。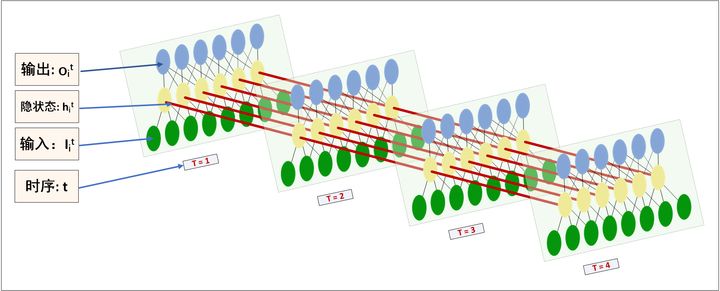
每个序列层都可以有给定size的C和h,这些是可以随着t传播下去的。而每个序列层的Y即为终点。这些用于存储的C和h越多,对历史数据的表征就越准确。
文本的表示
一段文本经过分词后,分解为一个由词语组成的向量。有以下几种表示法:
One-hot 所有独立单词在文本中出现的次数所生成的向量。
TF-IDF 除了单词在当前文本中的词频,还考虑了单词在所有文本集合中的词频。削弱那些在所有文本中都容易出现的单词的影响因子,从而用只在当前文本中出现频率高的词语来表征。
Word Embeddings 使用如维基百科等巨大语料库训练出的模型。它能用较低的维度来表征单词,且单词对应的向量表示能反映语义的相似性。换句话说,向量表示能隐含单词的上下文信息。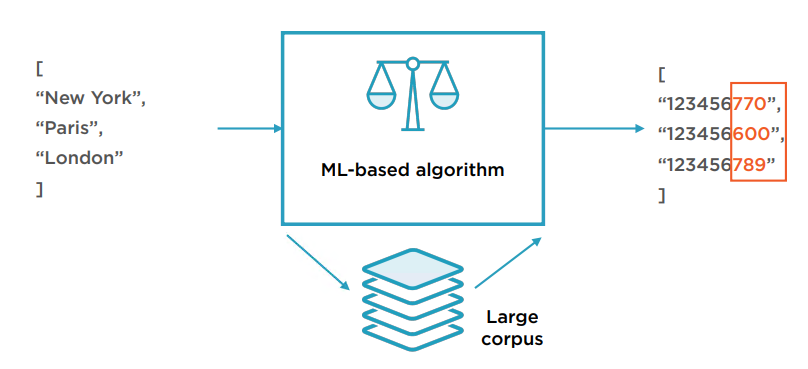
目前已经有成熟的预训练的Word embeddings库,如Google的Word2Vec和斯坦福的GLoVe。下面的例子展示了GLoVe的使用方法。
import torch
import torchtext.vocab
glove = torchtext.vocab.GloVe(name='6B', dim=100)#载入名为6B的模型,6B指该模型基于6个billion的token的语料库训练而成。 dim指维度数。glove.vectors.shape=torch.Size([400000, 100])
glove.itos[:15] #可根据索引返回对应token的字符串表示
glove.stoi['the'] #也可根据字符串返回索引值
#返回字符串的向量表示
def get_vector(embeddings, word):
assert word in embeddings.stoi, f'*{word}* is not in the vocab!'
return embeddings.vectors[embeddings.stoi[word]]
get_vector(glove, 'paper')
'''
tensor([-0.8503, 0.3336, -0.6589, -0.4987, 0.3659, -0.1925, 0.2566, -0.0534,
0.3147, 0.2443, 0.2934, -0.4492, 0.1517, 0.3931, -0.3179, 0.0605,
0.8177, -0.3885, 0.7676, -1.1041, -0.1544, 0.3165, -0.3724, -0.1148,
0.5163, -0.3929, 0.1630, -0.2532, -0.5098, 0.1520, 0.2781, 0.5252,
-0.3882, -0.3472, -0.6182, 0.1702, 0.1225, -0.2419, -0.3888, -0.5318,
-0.4699, -0.7050, -0.6213, -0.3869, -0.8564, -0.4100, -0.4749, -0.2108,
-0.8134, -0.5240, 0.4989, 0.3791, 0.5543, 1.1230, -0.4212, -1.5674,
-0.5689, 0.4082, 1.7949, 0.1686, -0.0029, 0.2879, -0.9009, -0.0942,
0.7999, -0.3910, 0.7629, 0.7131, 0.1319, -0.4076, -0.1869, 0.8956,
0.4687, -0.0029, 0.0253, 1.0084, 0.1714, 0.5974, -1.1003, 0.4931,
0.4178, 0.1728, -0.4947, 0.0878, -0.9669, -1.0920, 0.3390, -0.5129,
0.2464, 0.2714, 0.2421, -0.2171, 0.5504, 0.0082, -0.4557, 0.1353,
-0.0431, -0.4141, 0.7005, 0.1877])
'''
#返回单词的语义最近似的其他单词
def closest(embeddings, vector, n = 6):
distances = []
for neighbor in embeddings.itos:
distances.append((neighbor, torch.dist(vector, get_vector(embeddings, neighbor))))
return sorted(distances, key = lambda x: x[1])[:n]
def print_tuples(tuples):
for t in tuples:
print('(%.4f) %s' % (t[1], t[0]))
print_tuples(closest(glove, get_vector(glove, 'stupendous')))
'''
(0.0000) stupendous
(2.5795) marvellous
(2.7539) frightful
(2.8506) stupefying
(2.8561) awe-inspiring
(2.9179) mind-blowing
'''
#简单的语义类比可通过向量的加减法实现
def analogy(embeddings, w1, w2, w3, n = 6):
print('\n[%s : %s :: %s : ?]' % (w1, w2, w3))
closest_words = closest(embeddings, \
get_vector(embeddings, w2)
- get_vector(embeddings, w1) \
+ get_vector(embeddings, w3), \
n + 3)
closest_words = [x for x in closest_words if x[0] not in [w1, w2, w3]][:n]
return closest_words
print_tuples(analogy(glove, 'moon', 'night', 'sun'))
'''
[moon : night :: sun : ?]
(5.7069) morning
(5.7276) afternoon
(5.8023) evening
(6.1410) hours
(6.2797) saturday
(6.3056) sunday
'''
通过Word embeddings进行编码,将每个词语转化为一个给定长度的低维的数字向量,即可作为RNN网络的输入。
一个RNN接收一个固定长度的词语向量输入。因此在输入前还需对向量进行处理,使其完全贴合该长度。
1。对于少于给定长度的向量,要在最后加padding。
2。对于大于给定长度的向量,截断超出的部分。
3。对于未出现在词汇表里的词语,用特殊符号(如unk)标记。
下面是一个用RNN来做垃圾短信分类的例子。这是一个二分问题,即输出只有2个值。
比较难懂的是pytorch的LSTM的输入输出的定义。根据文档,定义如下:
输入
– input (seq_len, batch, input_size)
– h_0 (num_layers num_directions, batch, hidden_size)
– c_0 (num_layers num_directions, batch, hidden_size)
输出
– output (seq_len, batch, num_directions hidden_size)
– h_n (num_layers num_directions, batch, hidden_size)
– c_n (num_layers * num_directions, batch, hidden_size)
在此例子,为单向传播,令num_directions = 1,且只用到短期状态h则可简化为:
输入
– input (seq_len, batch, input_size)
– h_0 (num_layers, batch, hidden_size)
输出
– output (seq_len, batch, hidden_size)
– h_n (num_layers, batch, hidden_size)
– c_n (num_layers, batch, hidden_size) 【可忽略】
seq_len是指序列的那一维,在这里是词语在文本中的顺序。故seq_len=文本的长度。而hidden_size是每个序列层中短期状态的存储记忆单元的个数。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = pd.read_csv('datasets/ham-spam/spam.csv', encoding='latin-1')
data = data.drop(columns = ['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis = 1)
data = data.rename(index = str, columns = {'v1': 'labels', 'v2': 'text'}) #准备数据。labels为'ham'或'spam'。text为一段文本。
train, test = train_test_split(data, test_size = 0.2, random_state = 42)
train.reset_index(drop=True), test.reset_index(drop=True)
train.to_csv('datasets/ham-spam/train.csv', index=False)
test.to_csv('datasets/ham-spam/test.csv', index=False)
import numpy as np
import torch
import torchtext
from torchtext.data import Field, BucketIterator, TabularDataset
import nltk
nltk.download('punkt')
from nltk import word_tokenize #分词工具
#初始化torchtext的Field和LabelField,读取前面保存的csv文件,构建torchtext的训练集和测试集
TEXT = torchtext.data.Field(tokenize = word_tokenize)
LABEL = torchtext.data.LabelField(dtype = torch.float)
datafields = [("labels", LABEL), ("text", TEXT)]
trn, tst = torchtext.data.TabularDataset.splits(path = './datasets/ham-spam',
train = 'train.csv',
test = 'test.csv' ,
format = 'csv',
skip_header = True,
fields = datafields)
TEXT.build_vocab(trn, max_size = 10500)#按照词频从高到低的前10500个词语构建词汇表。词汇表另外还会追加2个词语:pad和unk。
#TEXT.build_vocab(trn, max_size= 10500, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_) #也可指定glove模型
LABEL.build_vocab(trn)
print(TEXT.vocab.freqs.most_common(50))#可查看前50高频词汇
print(TEXT.vocab.itos[:10])#按索引查看词汇表
print(LABEL.vocab.stoi) #defaultdict(None, {'ham': 0, 'spam': 1})
#使用以下迭代器,生成长度相似的文本batch数据,以尽量减少每个batch的padding。
batch_size = 64
train_iterator, test_iterator = torchtext.data.BucketIterator.splits(
(trn, tst),
batch_size = batch_size,
sort_key = lambda x: len(x.text),
sort_within_batch = False)
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(0.3)
def forward(self, text):
#pytorch内置的Embedding层,text is of size [sentence length,batch size],值为对应于词汇表中的索引。这里的sentence length是指在当前batch中包含词语最多的句子的词语数。那些小于sentence length的文本,将被padding到这个长度。注意到这里的sentence length,即序列长度,在每个batch中可以不同。而输出embedded is of size [sentence length,batch size, embedding dim]。
embedded = self.embedding(text)
embedded_dropout = self.dropout(embedded)
output, (hidden, _) = self.rnn(embedded_dropout)#返回值为:output of size [sentence length, batch size, hidden dim] and hidden of size [1, batch size, hidden dim]
hidden_1D = hidden.squeeze(0)
assert torch.equal(output[-1, :, :], hidden_1D)#最后一个output即为hidden
return self.fc(hidden_1D)
input_dim = len(TEXT.vocab)#按照文档,Embedding层是把词汇表size的维度,降到一个给定的维度。这里的输入等于词汇表的维度。
embedding_dim = 100
hidden_dim = 256
output_dim = 1
model = RNN(input_dim, embedding_dim, hidden_dim, output_dim)
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr = 1e-6)
criterion = nn.BCEWithLogitsLoss()
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)#输出为[batch size, 1]。因为第2维size为1,故可直接squeeze。
loss = criterion(predictions, batch.labels)
rounded_preds = torch.round(torch.sigmoid(predictions))
correct = (rounded_preds == batch.labels).float()
acc = correct.sum() / len(correct)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
num_epochs = 5
for epoch in range(num_epochs):
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
print(f'| Epoch: {epoch+1:02} | Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}% ')
#Model的评价
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in test_iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.labels)
rounded_preds = torch.round(torch.sigmoid(predictions))
correct = (rounded_preds == batch.labels).float()
acc = correct.sum() / len(correct)
epoch_loss += loss.item()
epoch_acc += acc.item()
test_loss = epoch_loss / len(test_iterator)
test_acc = epoch_acc / len(test_iterator)
print(f'| Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}% |')
多层RNN和双向RNN
多层RNN在原来的时间序列输入到输出之间再增加一个序列层。因此多了一层新的状态变量h。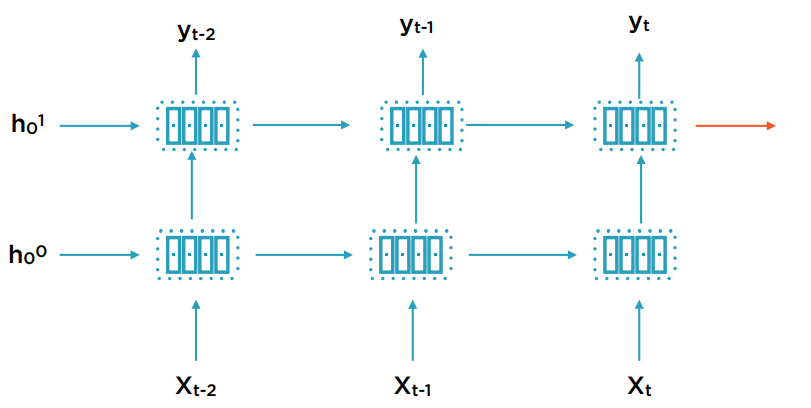
单向的RNN指前一个序列输出的状态变量会作为下一个序列的输入,双向则指后一个序列输出的状态变量也会输出到前一个序列。因此双向RNN也会多出一倍的状态变量h。这对于定长的batch数据(指将整个序列数据一次性输入)是合理的;但不适用于给定序列的一部分,来预测序列的另一部分。因为这相当于训练时知道了来自未来的信息。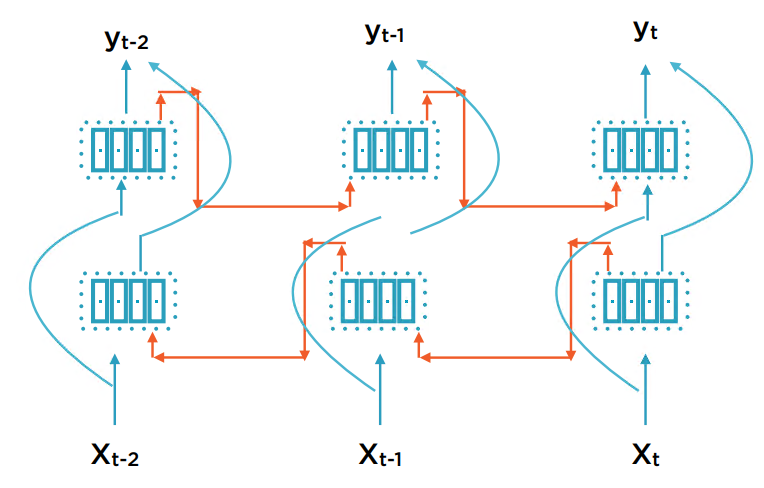
下面的例子使用和上面类似的方法,进行舆情分析。数据集为一段文本和对应的二元Label(正面or负面)。使用glove.6B.100d的Embedding模型。
TEXT.build_vocab(trn, max_size=25000,
vectors="glove.6B.100d",
unk_init=torch.Tensor.normal_)
使用GRU类来构建网络。因GRU多输出了一层hidden(2层正向和反向,共4层),我们简单将最后一层的2个hidden输出的向量相连,作为全连接的输入。所以全连接层输入为hidden节点数的2倍。
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim,
output_dim, n_layers, bidirectional, dropout):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.GRU(embedding_dim, hidden_dim, num_layers = n_layers,
bidirectional = bidirectional, dropout=dropout)
self.fc = nn.Linear(hidden_dim*2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text))
output, hidden = self.rnn(embedded)
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)) #2层双向,因此hidden层输出共有2×2=4个输出。hidden is of size [n_layers*2, batch_size, hidden_dim]
return self.fc(hidden.squeeze(0))
input_dim = len(TEXT.vocab)
embedding_dim = 100#使用的glove模型为100d
hidden_dim = 20
output_dim = 1
n_layers = 2
bidirectional = True
dropout = 0.5
model = RNN(input_dim,
embedding_dim,
hidden_dim,
output_dim,
n_layers,
bidirectional,
dropout)
另外,需将glove的预训练参数拷贝到模型的embedding层里。因glove模型不含
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
unk_idx = TEXT.vocab.stoi[TEXT.unk_token]
pad_idx = TEXT.vocab.stoi[TEXT.pad_token]
model.embedding.weight.data[unk_idx] = torch.zeros(embedding_dim)
model.embedding.weight.data[pad_idx] = torch.zeros(embedding_dim)
其余部分与上一个例子类似。