神经网络学习笔记(4) – 过拟合(Overfitting)
如下图所示,红色的点为训练数据。我们把这些点直接相连形成曲线。这条曲线确实能100%描述训练样本,但当验证来自同一原始样本的测试数据(绿色的点)时,正确率则为0。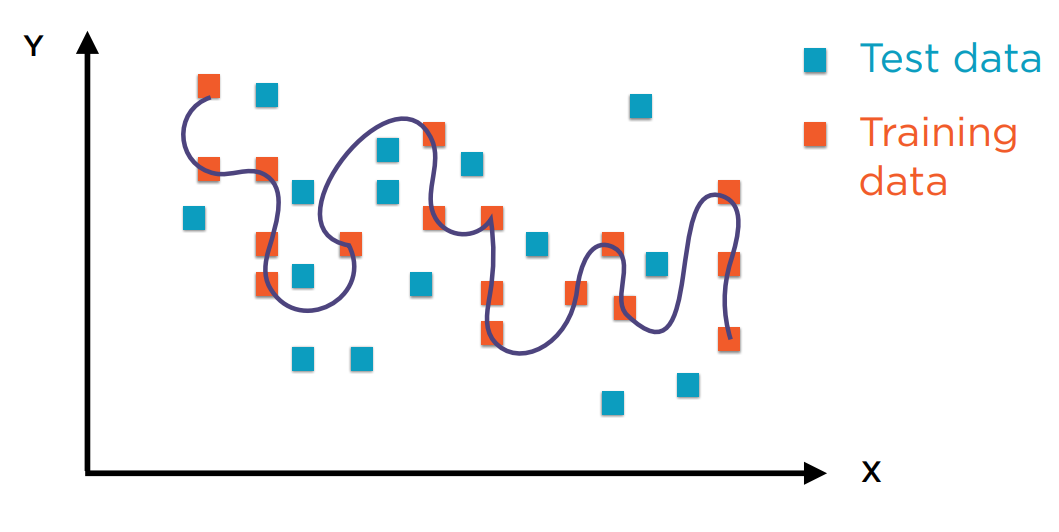
相反如果只用一条简单的直线来描述训练样本,虽然训练样本的准确率下降了,但测试样本的准确率提升了。毕竟评价一个模型的好坏应基于测试数据。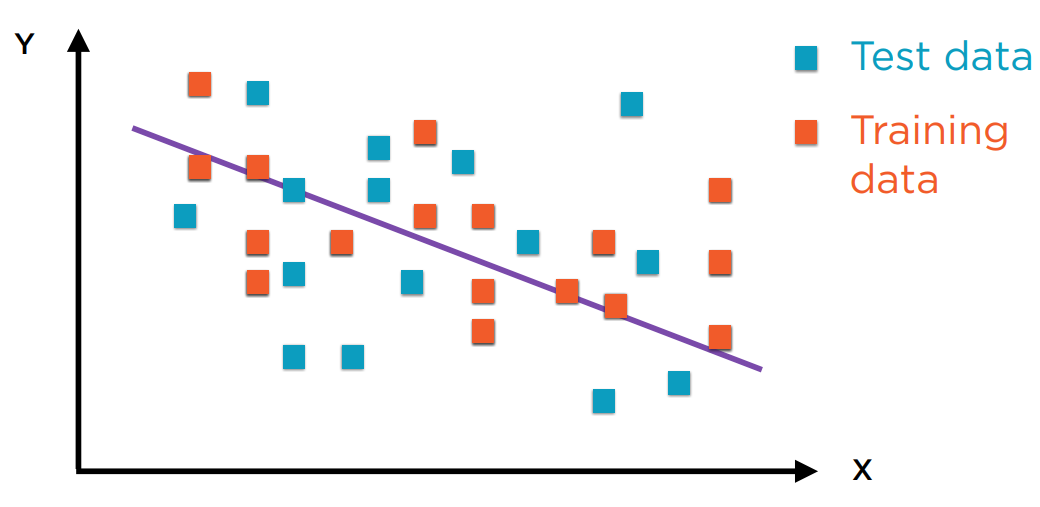
这种在训练时表现出色,但实际测试时表现很差的现象,就是过拟合。
为了防止过拟合。主要有3种方法:正则化(Regularization)、交叉验证(Cross-validation)和Dropout。
正则化
正则化也是一种数学技巧,它在优化的目标函数后追加了一个约束条件,以一个大于等于0的式子表示。正则化能降低方差(variance),但会造成偏差(Bias)。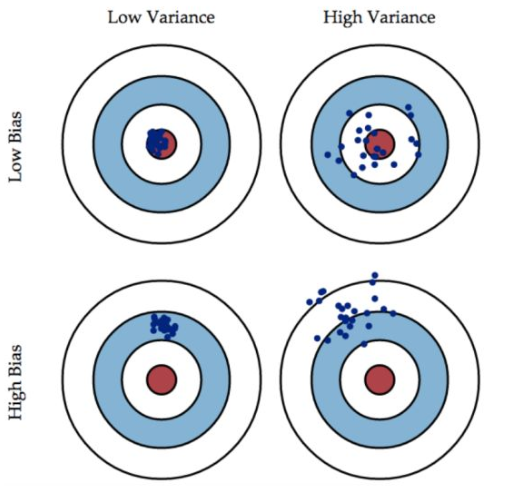
如之前的线性拟合问题,原来的Cost Function为:
添加正则化项,变成
其中,
交叉验证
交叉验证则着眼于对原始数据的分类上,除了训练集-测试集的方式,还有其他分类法能降低过拟合的机会。
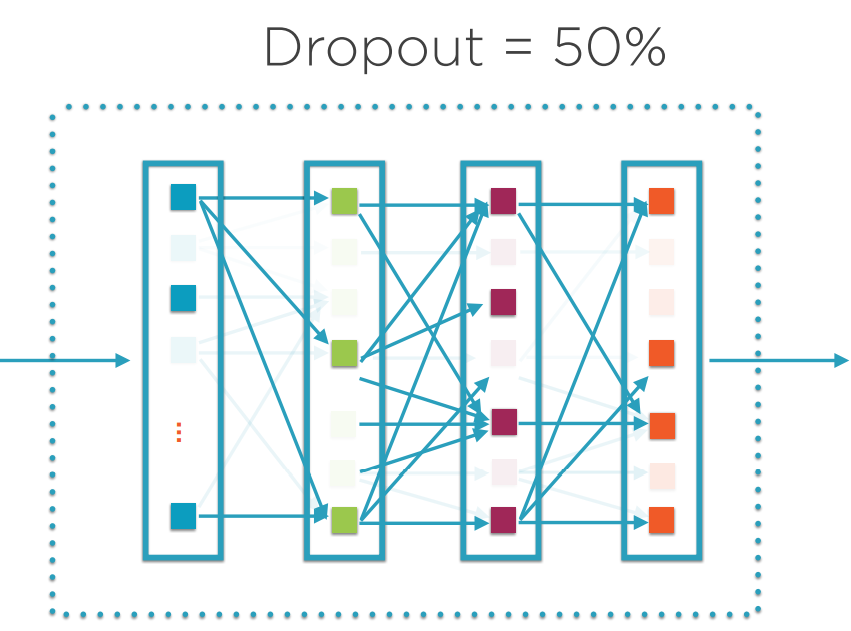
Dropout
Dropout是神经网络特有的一种解决过拟合的方法。其思想非常简单:在训练时随机地关闭一些神经元间的通路,使每次迭代时产生不同的网络。而在运行时,不执行Dropout,所有通路都被激活。Dropout的概率为一个需指定的Hyper Parameter。