神经网络学习笔记(1) – 深度神经网络简介
神经网络与机器学习
神经网络是一种基于机器学习的分类器。它有两个基本的阶段:训练和预测。在训练阶段,从某数据集读取大量被正确分类的样本,通过计算Loss Function提供反馈,训练自己的参数,从而在预测阶段能对一个新出现的样本进行分类。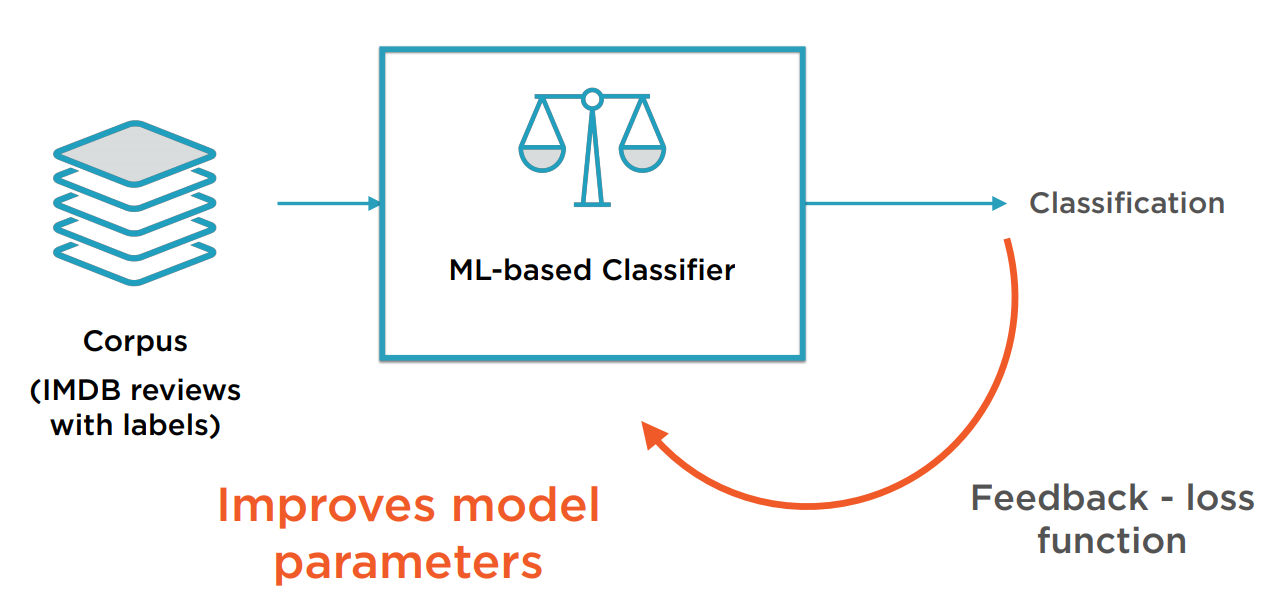
传统的机器学习需要专家来提供特征(Feature),而神经网络能在一定程度上减少人工对特征发现的干预。神经网络能自己发现数据的特征。
神经网络的结构
神经网络可以定义有很多层。层数比较多的就是深度神经网络。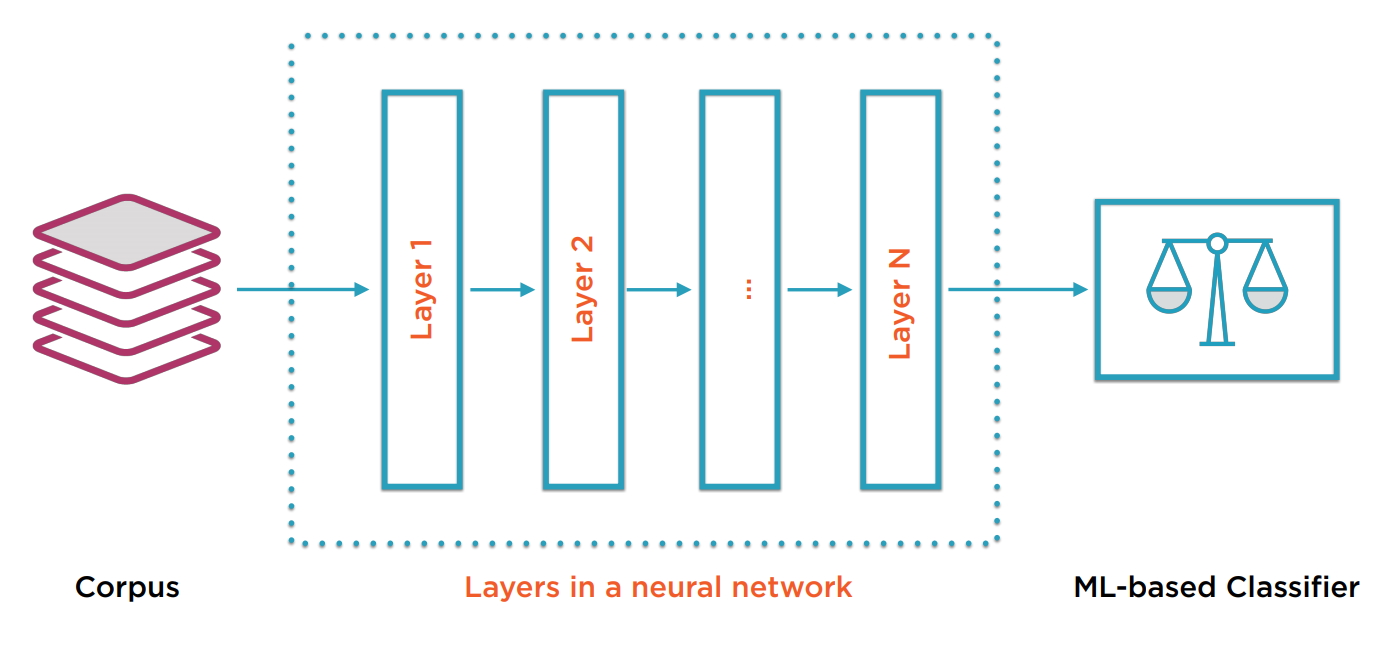
夹在中间的诸多层无法直接被外侧交互,也无法被人诠释,这就是隐藏层。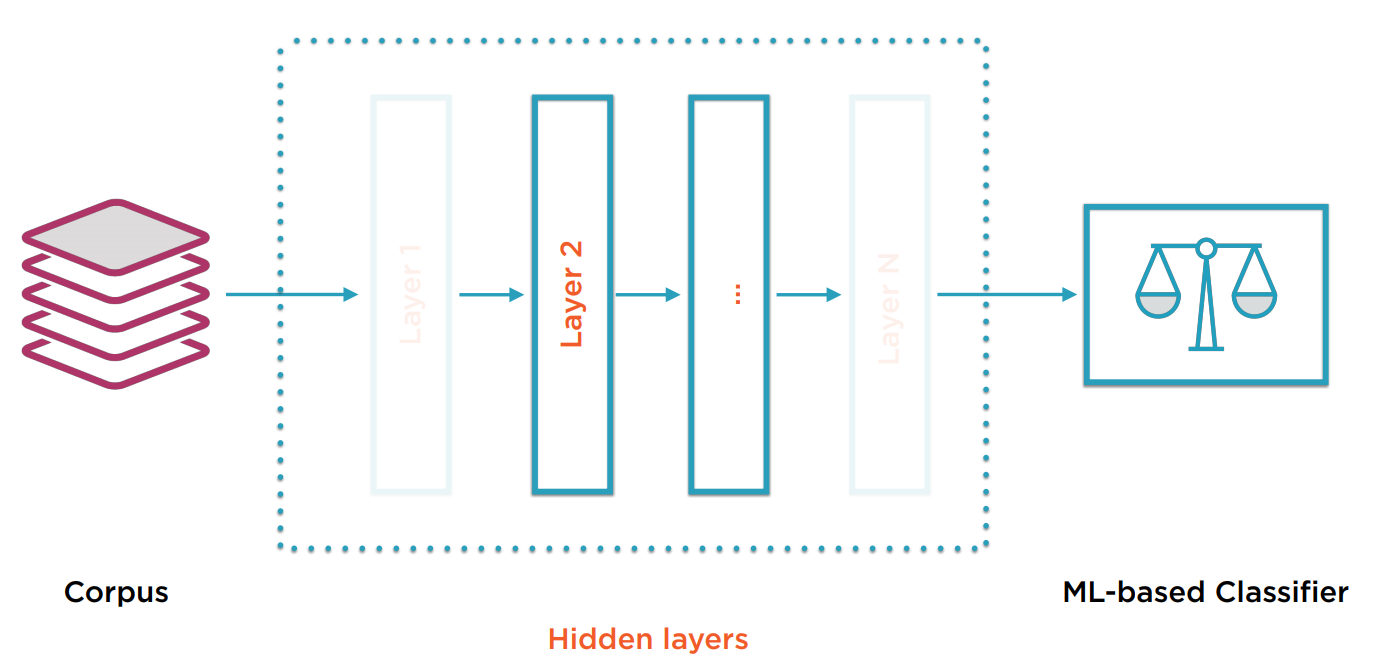
而每个层是由一系列的神经元排列而成。神经元是学习的最小单元。每个神经元和上一层或下一次层的神经元有连接。下图是一个全连接的例子。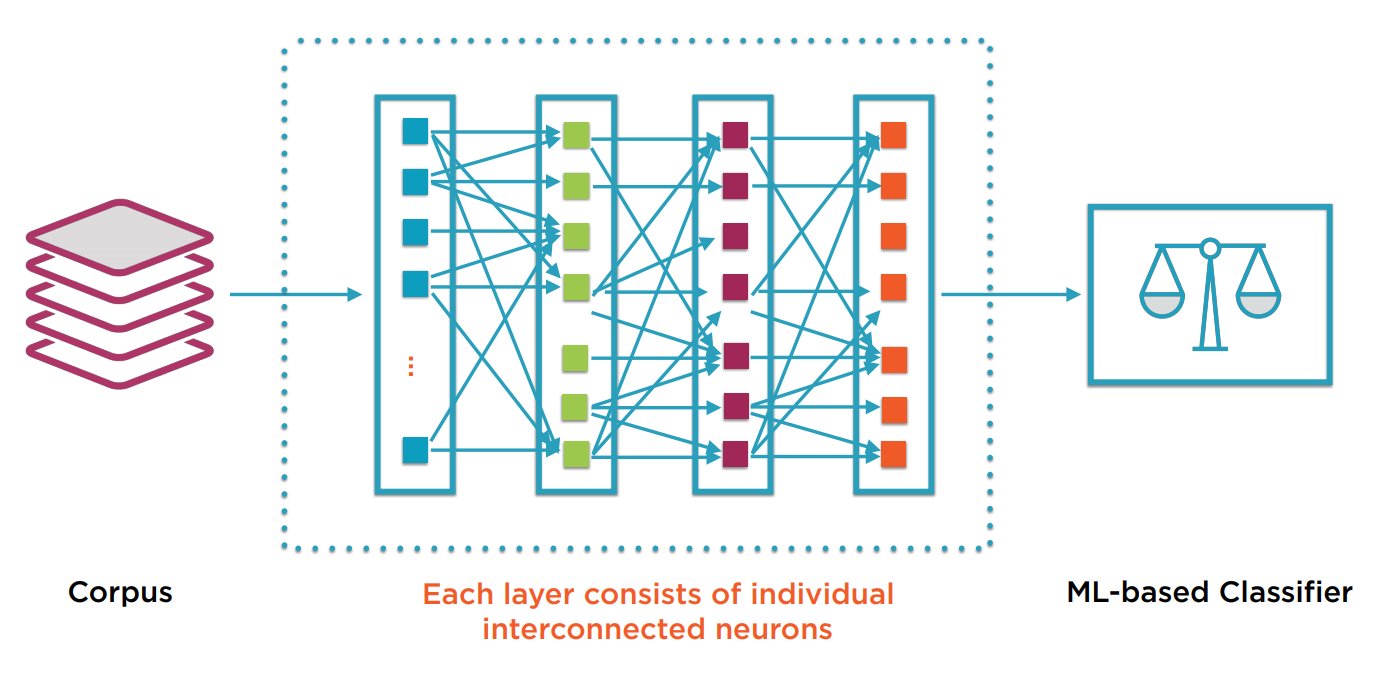
可以看出,一个神经元有若干输入连接,和若干输出连接。我们把输入的值记为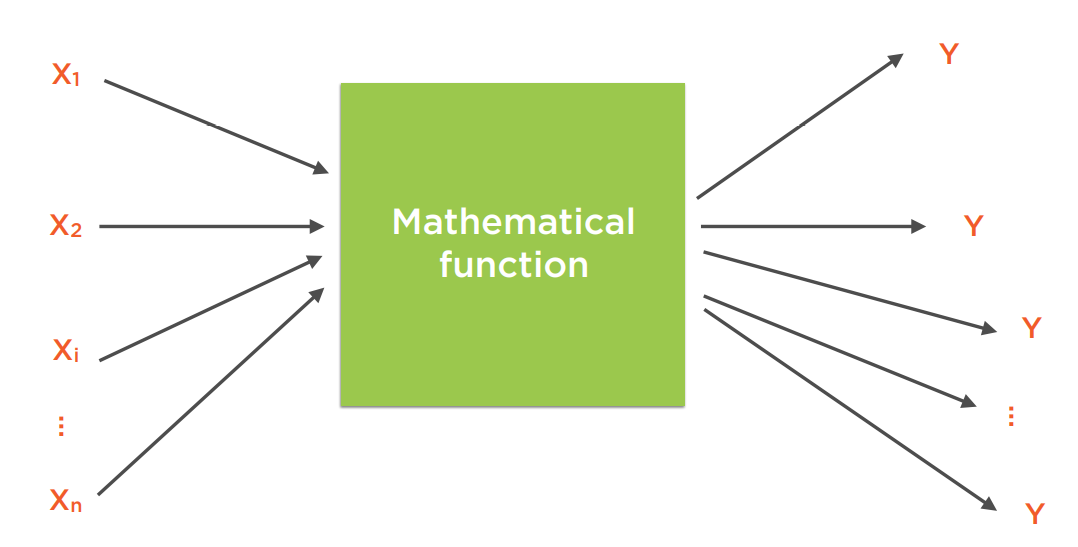
输出的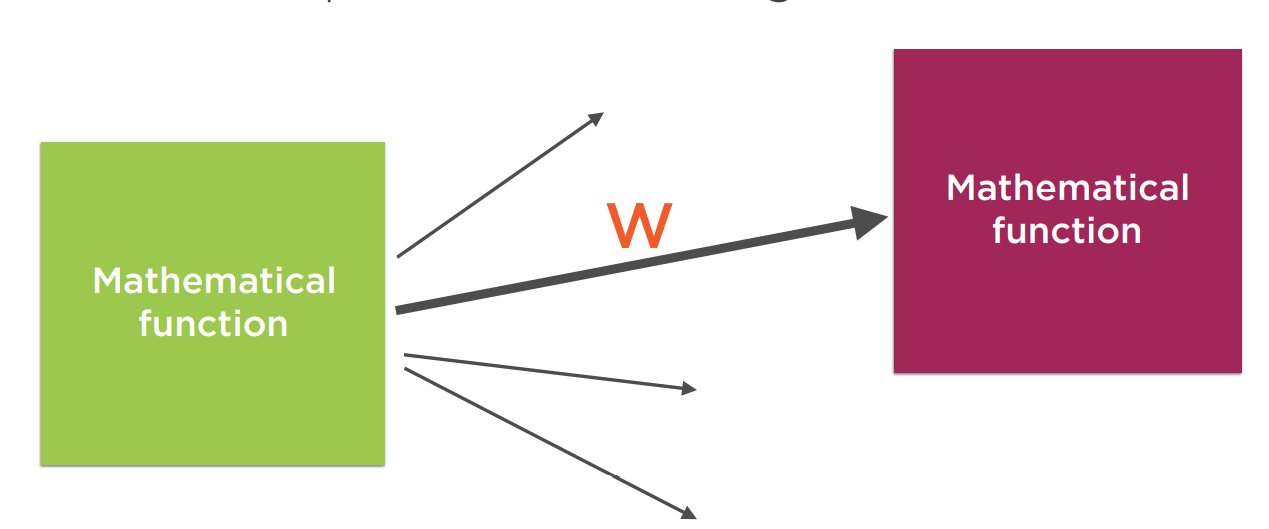
神经元内部的操作
神经元内部有两步操作。仿射变换(Affine Transformation)和激活函数(Activation Function)。
仿射变换其实是简单的向量的线性叠加。它用于发现线性规律。在这个例子里,就是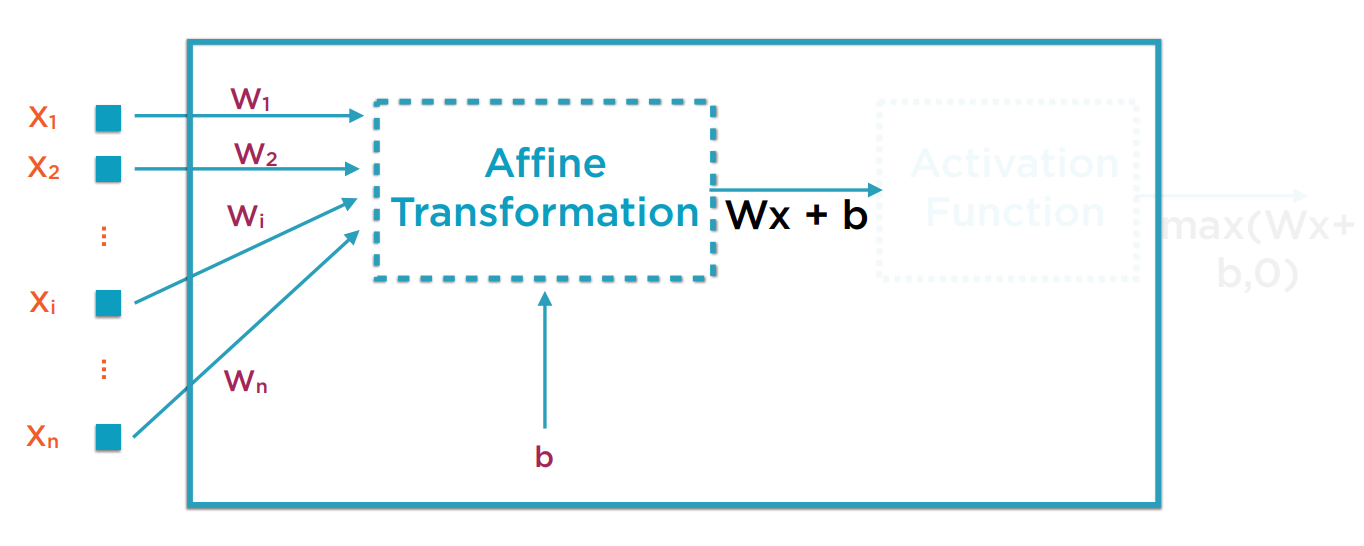
激活函数有各种可选项。它用于发现非线性规律。在这个例子里,是ReLU函数。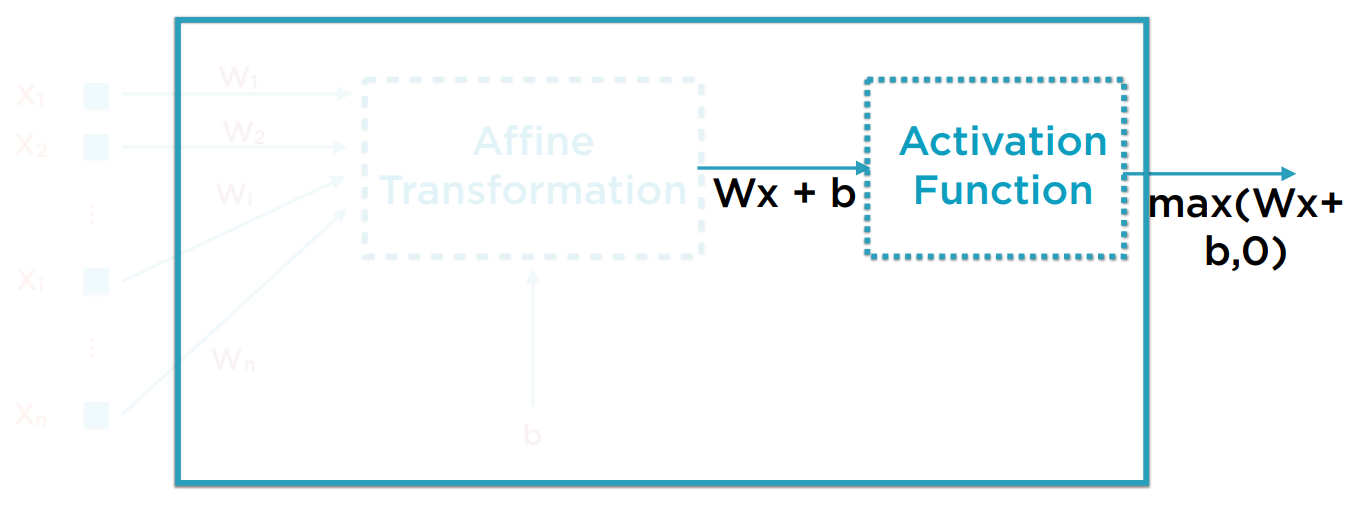
以下是几种常见的激活函数。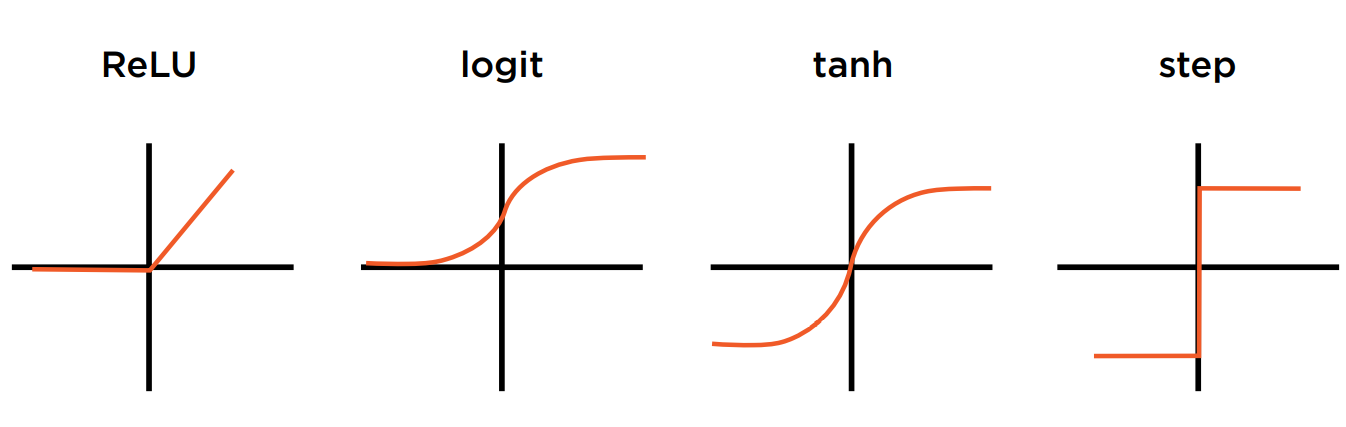
ReLU是常用的激活函数。全称是Rectified Linear Unit。它的表达式是
logit曲线(也叫SoftMax)也很常用。常被用于离散值的分类问题。
整个训练阶段就是要训练在网络中所有的